

A few years ago, I built a primitive computer vision music player (Oracle) using analog video and a basic threshold detector with an Arduino. Since then, outboard AI vision modules have gotten much more specialized and powerful. I decided to try an advanced build of Oracle using the new Grove Vision AI Module V2.
This post describes the approach and build, as well as a few pitfalls to avoid. Seeed sent me one of their boards for free and that was the motivation to try this out. Ultimately, I want to use the lessons learned here to finish a more comprehensive build of Oracle with more capability. This particular project is called Skulls because of the plastic skulls and teeth used for training and inference targeting.
The components are a Grove Vision AI Module V2 (retails for about $26) with an Xiao ESP32 C3 as a controller and interface. The data from the object recognition gets passed to an old Raspberry Pi 3 model A+ using MQTT. The Pi runs Mosquitto as an MQTT broker and client, as well as Fluidsynth to play the resulting music. A generic 8226 board is used as a WiFi access point to connect the two assemblies wirelessly.
What worked
Assembling the hardware was very simple. The AI Module is very small and mated well with an ESP32. Each board has a separate USB connector. The AI Module needs that for uploading models and checking the camera feed. The ESP32 worked with the standard Arduino IDE. I added the custom board libraries from Seeed to ensure compatibility.
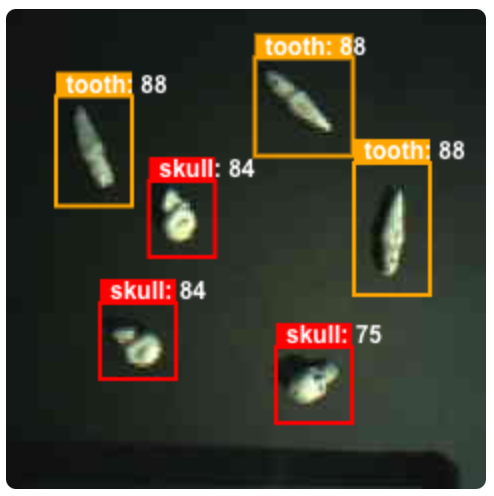
In the beginning I did most of the AI work directly connected to the AI Module and not through the ESP32. It was the only way to see a video feed of what I was getting.
One of the reasons I put so much effort into this project was to use custom AI models. I wasn’t interested in doing yet another demo of a face recognition or pets or whatever. I’m interested in exploring new human-machine interfaces for creative output. This particular module has the ability to use custom models.
So, I tried to follow the Seeed instructions for creating a model. It was incredibly time consuming and there were many problems. The most effective tip I can offer is to use the actual camera connected to the board to generate training images AND to clean-up those images in Photoshop or Gimp. I went through a lot of trial and error with paramters and context. Having clean images fixed a lot of the recognition issues. I generated and annotated 176 images for training. That took 5-6 hours and the actual training in the Collab notebook took 2-3 hours with different options.
Here is my recipe:
- Use a simple Arduino sketch to record jpegs from the camera onto an SD card.
- In an image editor, apply Reduce Noise and Levels to the images to normalize them. Don’t use “Auto Levels” or any other automatic toning.
- The images will be 240px X 240px. Leave them that size. Don’t export larger.
- In Roboflow choose “Object Detection”, not “Instance Segmentation”, for the project.
- When annotating, choose consistent spacing between your bounding box and the edges of your object.
- Yes, you can annotate multiple objects in a single image. It’s recommended.
- For preprocessing, I chose “Filter Null and “Grayscale”.
- For augmentation, I chose “Rotate 90”, “Rotation”, and “Cutout”. I did NOT use “Mosaic” as recommended in the Seeed Wiki. That treatment already happens in the Collab training script.
- I exported the dataset using JSON > COCO. None of the other options were relevant.
- The example Google Collab notebook I used was the rock/paper/scissors version (Gesture_Detection_Swift-YOLO_192). I only had a few objects and it was the most relevant.
- I left the image size at 192×192 and trained for 150 epochs. The resulting TFLite INT8 model was 10.9mb.
- I used the recommend web tool to connect directly to the AI Module and upload the model. It took multiple tries.
- On the ESP32 I installed MQTT and used that to transmit the data to my Raspberry Pi. I did not use the on-board wifi/MQTT setup of the AI Module.
This was a difficult project because of very confusing and incomplete documentation at mutiple stages. It’s clear to me that the larger companies don’t actually want us to be able to do all this ourselves. There were times it felt intentionally obfuscated to force me to buy a premium tier and some unrelated commercial application. I’m glad I did it though, because I learned some important concepts and limitations of AI training.
Demo
Conclusion
I’ll use this knowledge to finish a new build of the actual Oracle music composition platform I started. This particular demo is interesting, but a somewhat unpredictable and technically fragile. I found the research on generative music to be the most interesting part. As for the AI, I’m sure all this will be simplified and optimized in the future. I just hope the technology stays open enough for artists to use independently.