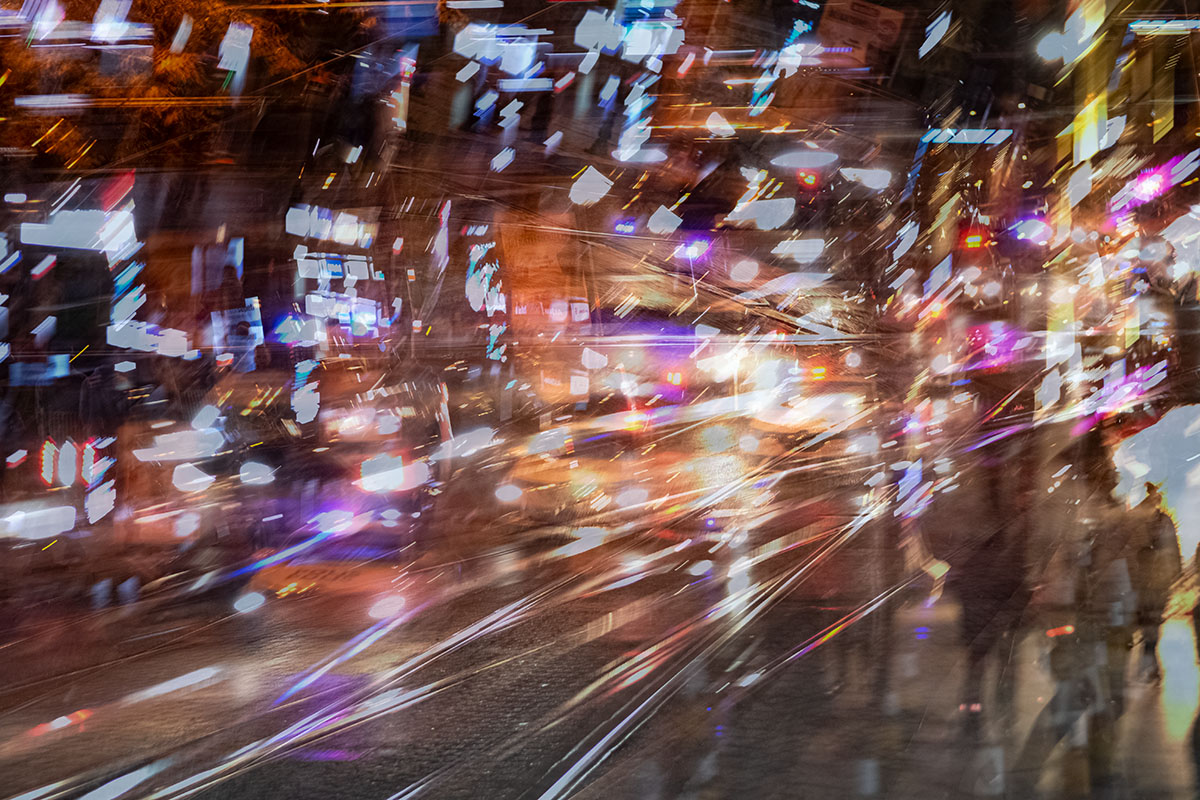I left Berlin at the end of this year. I had a specific vision for living in Berlin and I feel like I manifested that. I asked Berlin for a lot and it gave me plenty.
This post is part of a series (2022, 2023, 2024) that I made while there. Although it focuses on projects of this year, I have some closing thoughts on living in Berlin in general.
Slitscan
I made use of a custom slitscan camera this year. It was an interesting shift in my approach to photography. I don’t usually go for exotic photographic processes, but this intrigued me.
Last year, I met a guy named Ralph Nivens at the Experimental Photography Festival. His demo of perception bending slitscan photos was a highlight of the festival. I approached him afterward to find out how he made the cameras. He offered to make me one and it finally arrived in January of this year.
The basic idea of the camera is that it captures images in a series of very thin slices and then assembles them as a single coherent image. Each frame of the camera is 1 pixel wide by 4096 pixels high. It’s very close to a flatbed scanner, but upright and with a lens attached. Nivens wrote the firmware for the camera himself and 3D printed the body.


The exposures are quite long, 10 seconds to 2 minutes. The individual slice captures are pretty fast though, almost standard shutter speed of 1/60 of a second. Because the exposure is so long and the final picture is assembled, you get some crazy time dilation artifacts. Anything moving in front of the camera gets compressed or expanded depending on the speed of the movement. Below is a street scene and the tall stripes are people. They have been compressed because they walked quickly in the opposite direction of the capture order.

In general, Germans don’t like to be photographed in public and are very conscious of privacy. This was true when I was doing my street exposures. People gave me grumpy looks and one woman was particularly angry. Open street photography is quite legal in Germany (I looked it up). So, I tried to argue with her, but she insisted that I stop and leave. I didn’t, so she tried to grab the camera. My limited German is not good enough for conflict like that and I also didn’t want to hurt her. Fortunately, others on the street heard the commotion and talked her down. We both walked away and the drama ended with that.

I kept making images throughout the winter and decided to experiment with the files generated by the camera. They are monochromatic, so as an RGB image all color channels are the same value. R:200 G:200 B:200 and so on. It’s possible to swap and blend channels from different images to yield unique color combinations.
I wrote a Python script to swap all the channels of folders full of images. That yielded some spectacular color results. It also generates images with unaesthetic collisions of values. My approach was to keep generating the swaps until interesting image combinations happened. Below are combinations of 2 and 3 channel variants.
A larger group of these ended up in my solo show later in the year. The prints were tricky because some of the colors were way out of the printer’s color range.



Echospheric Workshops
I was part of the Echospheric sound art collective this year. We organized and taught multiple workshops at HB55 in Lichtenberg. My part was to teach Arduino-based synthesizer workshops. I have been building little synths for a few years and have a good recipe for experimental sound boxes. The first workshop was just a presentation but the second was a fully developed fabrication workshop.

I put together kits for each student so they could build the synths without soldering. That simplified the in-person experience and still yielded a versatile sound device they could take home.




I had to tune the instruction to a wide variety of technical expertise. Some had never done anything like this and others were fairly advanced. Keeping all skill levels engaged and informed was challenging. But, it worked and they all produced squawking sound machines. The response from the students was excellent and I’m glad I had the chance to teach like that.

Singing Heart
My friend Benjamin Kjellman-Chapin is a blacksmith in Nes Verk, Norway. We went to the Atlanta College of Art together back in the nineties. I visited him last year and saw his expansive setup there. He is doing some amazing work.
This year he was putting together some work for a solo show and asked if I wanted to collaborate on one his pieces, Singing Heart. The idea was to craft a large steel heart and put electronics inside that made sound when the heart was moved. It was an unusual and fantastic project.



My part of the project was complicated because of the limits of the chips I bought. I picked devices that looked good on paper, but I hadn’t used them before. When they arrived, there were problems with the different driver libraries. Just because something is theoretically possible doesn’t mean it’s easy. I ran into issues that could only be solved by using a different chip set.
It also needed to be rechargeable and that had its own needs and limitations. For instance, buying raw lithium batteries and having them shipped in Europe is a special customs arrangement.
I also had to come up with the actual singing. I didn’t have access to a choir or professional singers, but I do have Reason. It’s a platform for making music on a computer and both of my albums were made with it. But, it’s more for electronic music than high fidelity synthetic singing. I found a plug-in that came pretty close and composed some basic melodies and voice blends. It was psychedelic to be in my little apartment and making hours and hours of angelic singing.
I finished the first prototype and sent him some videos. There were tweaks and adjustments and then I had a final assembly completed. I was happy with what I had made, but I know from experience that these things have to survive unpredictable environments. I did my best to seal it up and reinforce the connections.
The final result was interesting and engaging. Ben got some flattering comments from people at the show. For me, it was a great opportunity to make something cool with someone I have a lot of respect for.
Gelli Prints
I found my rhythm with a new process for printmaking. It is an effective bridge between photography, computer work, and traditional art practices. It’s called Gelli printing. Instead of a stone, it uses a slab of gelatin as a transfer surface. Acrylic paint is thinly applied on top and then removed, blended, or textured in a variety of ways. The result is a monotype: a one of a kind print.
It doesn’t require other specialized equipment like a press or engraving/cutting tools. The “plate” is actually a laser print that gets consumed with each print. The laser toner resists the paint and the paper absorbs it. When you lay a print on the applied paint, some paint is removed and some is left. The result is a fairly detailed image transfer in whatever color paint was used.
That can be repeated, layered, manipulated, and stenciled. The possibilities are diverse. I used a many layered technique that had a few detailed images blended with texture layers and surface manipulation. If you’re looking for fidelity and consistency, this is not the process you want. I did the exact same thing multiple times and got completely different results. You have to surrender to the process in many ways.


I used the kitchen counter of my tiny flat for printmaking. It would be set up like this for months at a time. That made it difficult to cook complex meals but I worked around it.

Above is a gelatin block with paint applied. It’s ready for more layers or to get printed. All the newspaper was to make sure I didn’t ruin the counter. I wanted to get my deposit back eventually.


I spent around 3 months printing like this throughout the year. I think the main benefit of this process was that I didn’t need to go somewhere else to work. I would make prints or begin layers at the beginning of the day and then finish them off later. It became a daily practice that was responsive to different feelings and experiences. It wasn’t a diary, but something more like a sketchbook.
I produced over 300 monotypes this way. A small edit of those became the bulk of my solo show in Fall. The others are being cut, collaged, and re-used in all kinds of ways.
Finland
The Helsinki Biennial was an unexpected mind blower, but the real highlight was meeting my long lost uncle.
Helsinki Biennial
I didn’t know anything about the Helsinki Biennial before I decided to visit Finland. It came up as something to check out as a side quest while I was in Helsinki. It turned out to be an incredible collection of contemporary art and was vastly superior to what I saw at Documenta a few years ago.
Organized by HAM (Helsinki Art Museum), most of the event is on Vallisaari island in the bay of Helsinki. There were 37 artists and collectives represented in a vast array of installations on the island and also the main museum.
The level of craft, concept, and execution was exceptional. Many of the pieces incorporated sound art in well-thought-out ways.













Maija Lavonen
While exploring Helsinki, I visited ADmuseo (Architecture & Design Museum). It had an incredible show of fiber optic tapestries and sculptures by Maija Lavonen. They blend classic techniques of weaving from Finnish culture with the material that carries most of the internet around. These things had a real presence that was more than technical novelty. There was a lot of feeling and history.









Uncle Mauri
My uncle Mauri was only known through sparse stories in my family. On my mother’s side, I have 4 uncles. Altogether, they are the 5 children of Hannah, my grandmother. Most were born in Illinois and raised as an American family. Mauri was born in Finland, as the first child of Hannah. He grew up completely separate from the rest of the family.
Nobody had actually talked to him. There were a couple of letters in the 70s but that’s it. We knew where he was because Hannah’s ashes were sent to him when she passed. Since Helsinki was an easy flight from Berlin, I decided to meet the man.
I found an old phone number in a tax record online. I had a feeling it might work, but I spoke no Finnish. I found someone in Berlin who was from Finland and she agreed to call him for me. She came over and we sat on my couch and dialed the number.
He actually picked up right away and I was relieved to have a Finnish speaker there. He was initially skeptical (can you blame him?), but was willing to begin communications. We decided to exchange emails for a while because we could use online translation tools.
We emailed for 8 months and then I suggested a visit. He was receptive and we made the plan. I was excited to meet him, but had no idea what to expect.

In Helsinki, he picked me up in his van and visited my grandmother’s gravesite that he had arranged. We didn’t know each other’s language so the 30 minute ride was in silence, except for the radio. It was very strange, but somehow totally familiar because of the long car rides I took with my uncles in Georgia as a child. I felt like I knew him.
We figured out how to use Google translate in conversation mode on my phone when we got to the cemetery. It’s not foolproof, but is fairly effective if you choose short and plain statements to make. After the grave visit we came back to Helsinki and sat in a coffee shop for a few hours, talking through the translator.
The connection was immediate and openhearted. We shared family histories and personal stories. Some were very difficult and others were funny and exciting. I’m not going put them in a blog post like this, but they covered the full range of human experience.

A twist of fate as a teenager brought Mauri to a ballet studio. The teacher needed him to support the female dancers. He gained a love of dance and spent the next 20 years as a professional dancer in Finland. He was in Hair, West Side Story, and many Finnish productions.

After a long dance career he ended up was a contractor and handyman and raised 4 kids. He had a barn with 3 workshops inside, with a whole array of carpentry projects.

My time with Mauri was heartfelt and genuine. It’s amazing to make a family connection like that after so many years. Of all the things I came back from Berlin with, a new uncle is the most amazing.
Der Wendepunkt
I had a large solo show of recent work in early September. It was during Berlin Art Week and located at an unusual space inside the Alexanderplatz transit station. The whole experience was weird, fulfilling, and challenging.

Back in May, I saw a post by Culterim about a new art space they were making available. It was an empty cosmetic store in Alexanderplatz. I saw the photos of the inside and knew it was perfect to show what I had made this year. I also saw an opportunity to have a non-traditional show during Berlin Art Week at a central location.
Alexanderplatz is not a prestigious place. In fact, many Berliners despise it because of the crowds and commercial vibe of the surrounding complex. When I told friends I was having a show there, most were confused.
To me, it represented a chance to show art directly to regular people in a humble environment. I knew I would get all kinds of people in there. Tens of thousands go through that station each day. It was a chance to reach a broad range of people outside of the Berlin art bubble.

There was no gallery staff or assistants. I had to handle every aspect of that show from hanging to marketing to sitting in the gallery itself during open hours. I hung that whole show in about 6 hours, with levels and magnets. That included carrying all the artwork down there on the tram.






The work I showed was monotypes, lino prints, photography, and some small installations. Most of it was made this year. It was cool to have a lot of work to choose from. This has been one of the most prolific times of my life.






On Saturday night, I did a noise performance with the synths I made in Berlin. Although short, it was loud. The sound reverberated around the entire station. People were streaming in the side doors to see what was happening. It probably sounded like one of the trains had crashed.
I look at this as my exit show for the whole Berlin cycle. It’s a good anchor point for this time in my life. I didn’t sell any work or make important gallery contacts. It wasn’t meant for that anyway. I got exactly what I wanted out of that experience: a chance to reflect my experience in Berlin back to the city itself. It wasn’t about achievement. It was about connection.
Buchstabenmuseum
I got another opportunity to use my 10X technique for making photos. Buchstabenmuseum was a museum in Berlin dedicated to classic backlit and neon signs from multiple eras of Berlin. They lost their space and announced a last chance to see the collection.



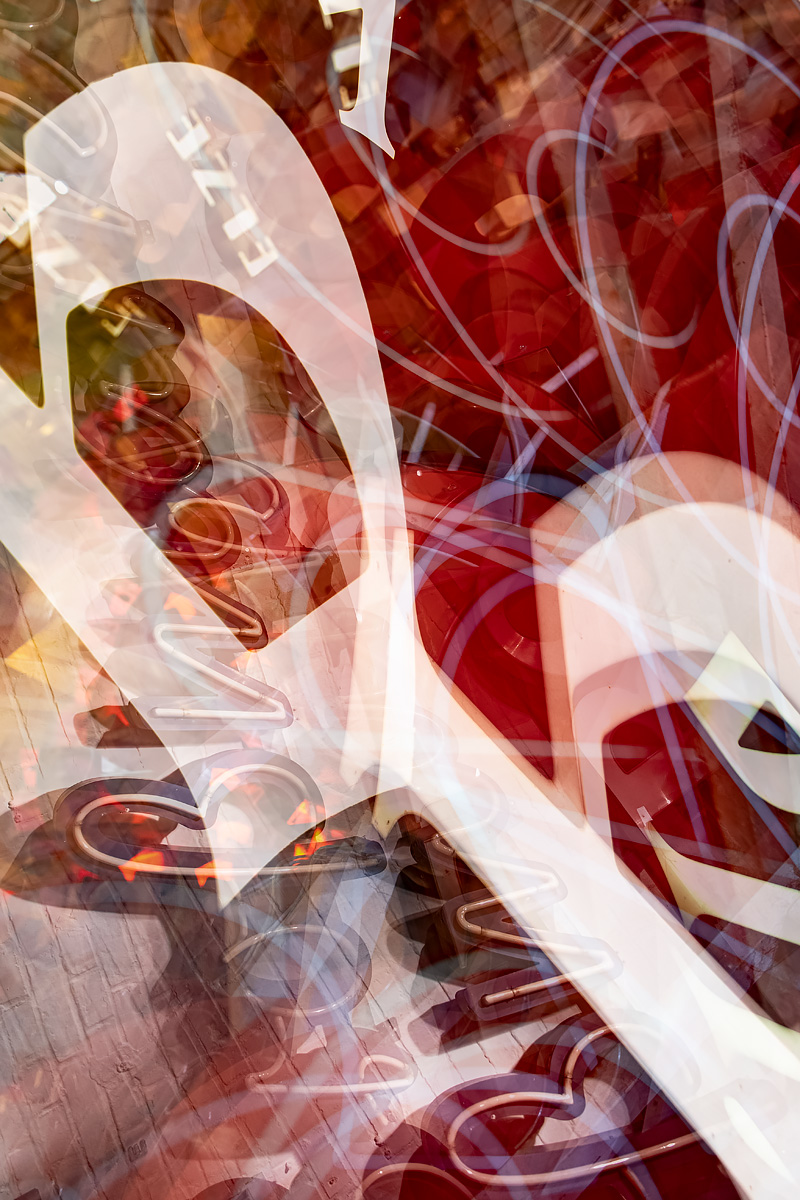


Making these reminded me of being in Reno, NV and making my first 10X photos during my cross-country drive. I like making connections like that now. They are reminders that beyond technique there is real human experience happening around all these images.
Paris
My last big trip within Europe was a visit to Paris. It was supposed to be amazing but it was just meh. But, I met some cousins there and being with them one last time was great.
I didn’t do much passive tourism in the 4 years I was in Europe. My trips were mostly about art events or personal connections. This time, I saw the sights and kinda cruised around.
For museums, I had an inside track. I was a member of a German artist union called the b.b.k. That had a few perks. One of those is free or discounted entrance to certain institutions. Not only did I get in free to the Louvre and Bourse de Commerce, I was let in through VIP entrances. Very fancy.
In fact, I was at the Louvre with my cousin Corrine just 12 hours before the infamous crown jewel heist. It was bizarre to read international news reports and see photos of where I had been standing the day before.
My favorite place was the Musée de la Chasse et de la Nature. It’s cross between a hunting lodge and a contemporary art museum. It’s unique among European art institutions. New art and old guns make a volatile mix.














Paris is an interesting city, but it was not the peak of my time in Europe. Too many people had told me I “have” to go there. I don’t see cities the way most people do and I’m much more interested in people than old buildings. I was in Europe to connect and participate, not to observe.
Final Thoughts
Now, I’m in San Francisco writing this blog post. After 4 years in Berlin, I moved back to California. It wasn’t sudden or dramatic. Nothing was wrong and nobody was in a hurry to have me back. It was just time.
I never intended to be an expat. I went to Berlin for a specific purpose and came back when I was done. Lots of people in Berlin and California asked me why I was moving back. Most were unsatisfied with my simple answer. They assumed there must be some drama behind it. Nope. No drama.
Most of the expat Americans I met in Berlin had no intention of returning. They had found their city and were settling in. I didn’t meet many that had lives I wanted. That’s not a judgment of them, just a recognition of my own values.
There is something else, though. Berlin is a special place when it comes to culture. There is lots of structure and funding and interested audiences. Those things are under pressure right now, but compared to America cities they have much more support in place. That structure is not portable. You can’t bring Berlin with you.
So, many artists stay there and want to be incubated. I wanted something to bring back. I wanted to learn how that ecosystem worked. I wanted to know what a city looks like when artists have a fighting chance at survival. I wanted to see how they organized and kept their communities alive.
There was no enlightenment at the mountaintop. I didn’t meet some guru that just laid it all out. What I found was a thousand artists living a thousand paths. But, that was enough.
I got to see all of it for myself. Then, I got multiple chances to take my turn. I had solo shows, group shows, online shows, performances, workshops, and collaborations. I made friends with other artists at all levels. I met gallery people (but not many) and talked to lots of institutional workers. I learned new techniques and then taught them to others. I got to experiment and fail without much drama. I just kept going. All that experience is coming back with me.
Self-determination. Collectivism. Experimentation. Ownership. That’s what it’s all about and that’s what I want to manifest in San Francisco.
Now comes the hard part. I picked one of the most expensive cities in the world to attempt all that. Way more expensive than Berlin. I don’t have some clever solution or plan. I’m just going to hack away at it month by month until I get something going. That’s what has worked so far.
I’ll close with my favorite German word, gelassenheit. It’s a heavy word with a light meaning. It signifies contentment or serenity. The root, lassen, is for letting, as in letting go. Gelassenheit is to be in the state of letting go.
Ich hoffe, die Zukunft bringt Gelassenheit.