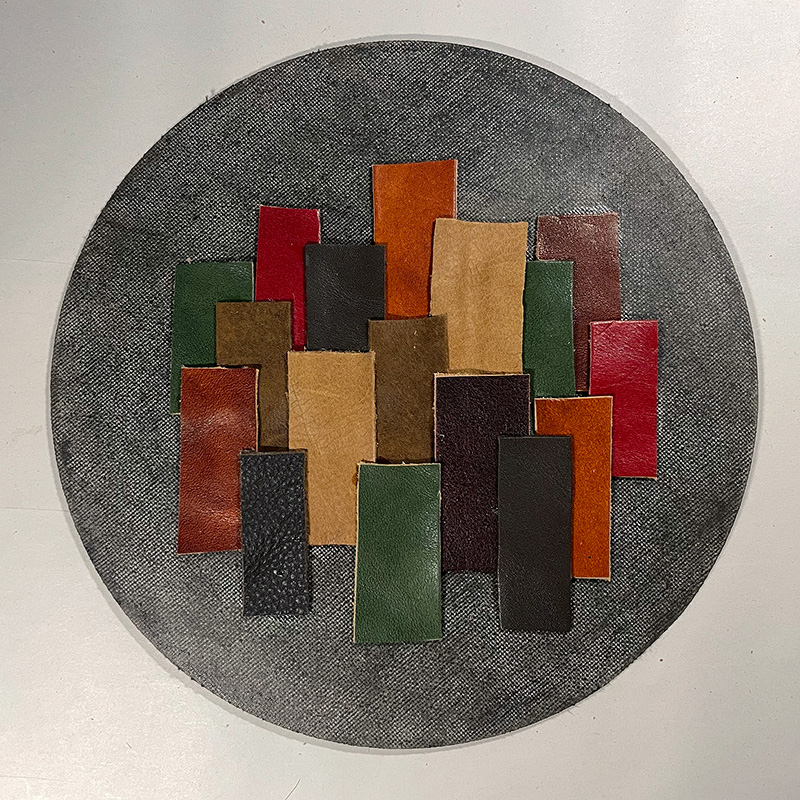A few years ago, I built a primitive computer vision music player (Oracle) using analog video and a basic threshold detector with an Arduino. Since then, outboard AI vision modules have gotten much more specialized and powerful. I decided to try an advanced build of Oracle using the new Grove Vision AI Module V2.
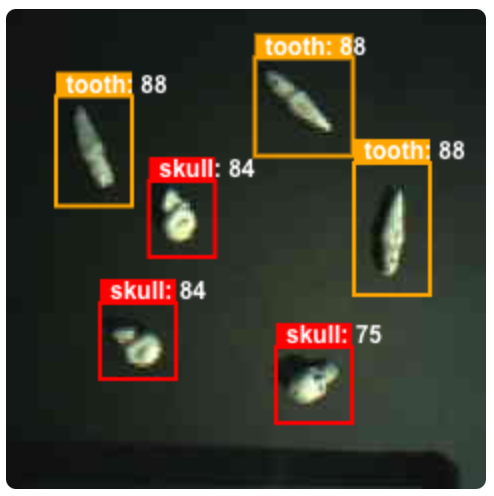
This post describes the approach and build, as well as a few pitfalls to avoid. Seeed sent me one of their boards for free and that was the motivation to try this out. Ultimately, I want to use the lessons learned here to finish a more comprehensive build of Oracle with more capability. This particular project is called Skulls because of the plastic skulls and teeth used for training and inference targeting.
The components are a Grove Vision AI Module V2 (retails for about $26) with an Xiao ESP32 C3 as a controller and interface. The data from the object recognition gets passed to an old Raspberry Pi 3 model A+ using MQTT. The Pi runs Mosquitto as an MQTT broker and client, as well as Fluidsynth to play the resulting music. A generic 8226 board is used as a WiFi access point to connect the two assemblies wirelessly.
What worked
Assembling the hardware was very simple. The AI Module is very small and mated well with an ESP32. Each board has a separate USB connector. The AI Module needs that for uploading models and checking the camera feed. The ESP32 worked with the standard Arduino IDE. I added the custom board libraries from Seeed to ensure compatibility.
In the beginning I did most of the AI work directly connected to the AI Module and not through the ESP32. It was the only way to see a video feed of what I was getting.
One of the reasons I put so much effort into this project was to use custom AI models. I wasn’t interested in doing yet another demo of a face recognition or pets or whatever. I’m interested in exploring new human-machine interfaces for creative output. This particular module has the ability to use custom models.
So, I tried to follow the Seeed instructions for creating a model. It was incredibly time consuming and there were many problems. The most effective tip I can offer is to use the actual camera connected to the board to generate training images AND to clean-up those images in Photoshop or Gimp. I went through a lot of trial and error with paramters and context. Having clean images fixed a lot of the recognition issues. I generated and annotated 176 images for training. That took 5-6 hours and the actual training in the Collab notebook took 2-3 hours with different options.
Here is my recipe:
Use a simple Arduino sketch to record jpegs from the camera onto an SD card.
In an image editor, apply Reduce Noise and Levels to the images to normalize them. Don’t use “Auto Levels” or any other automatic toning.
The images will be 240px X 240px. Leave them that size. Don’t export larger.
In Roboflow choose “Object Detection”, not “Instance Segmentation”, for the project.
When annotating, choose consistent spacing between your bounding box and the edges of your object.
Yes, you can annotate multiple objects in a single image. It’s recommended.
For preprocessing, I chose “Filter Null and “Grayscale”.
For augmentation, I chose “Rotate 90”, “Rotation”, and “Cutout”. I did NOT use “Mosaic” as recommended in the Seeed Wiki. That treatment already happens in the Collab training script.
I exported the dataset using JSON > COCO. None of the other options were relevant.
The example Google Collab notebook I used was the rock/paper/scissors version (Gesture_Detection_Swift-YOLO_192). I only had a few objects and it was the most relevant.
I left the image size at 192×192 and trained for 150 epochs. The resulting TFLite INT8 model was 10.9mb.
I used the recommend web tool to connect directly to the AI Module and upload the model. It took multiple tries.
On the ESP32 I installed MQTT and used that to transmit the data to my Raspberry Pi. I did not use the on-board wifi/MQTT setup of the AI Module.
This was a difficult project because of very confusing and incomplete documentation at mutiple stages. It’s clear to me that the larger companies don’t actually want us to be able to do all this ourselves. There were times it felt intentionally obfuscated to force me to buy a premium tier and some unrelated commercial application. I’m glad I did it though, because I learned some important concepts and limitations of AI training.
Demo
A demo of different sounds and arrangements produced by the assembly.
Conclusion
I’ll use this knowledge to finish a new build of the actual Oracle music composition platform I started. This particular demo is interesting, but a somewhat unpredictable and technically fragile. I found the research on generative music to be the most interesting part. As for the AI, I’m sure all this will be simplified and optimized in the future. I just hope the technology stays open enough for artists to use independently.
This year was filled with travel around Europe and also back to the USA. I had a new job and a stable place to live, so I explored further into Berlin and around the region. I had my first Berlin art show and started working in new mediums. Trips to Stockholm and London brought me in contact with the international art world and I learned more about how it works, for better or worse. A trip to Auschwitz was humbling and yielded insights into the human experience of that era. I have been here 2 years now and feel like there is still so much to experience.
Surrendering the San Jose studio
At the beginning of the year I flew back to San Jose, California to move out of my art studio. It was physically and economically difficult.
I had planned on maintaining that space until I returned. The cost of that was right up to the edge of what I could afford. The landlord notified everyone in the studio complex that he was raising rents 50-200%. Mine was set to double. There was no way I could afford that, so plans were made to fly back and put everything into storage and let go of the space. Fortunately, my new employer let me take a week off to do that. Waiting longer would have been even more expensive.
In addition to my power tools, art supplies and equipment, all of my personal belongings had been put there. It took 3 days just to consolidate and pack everything. Then, the actual moving took 3 more days by myself. It was around 7 U-Haul van loads in all. A lot of that shit was really heavy. I was still dealing with 9 hour jet lag as well.
I found a good storage spot, though. It’s secure, weather protected, and reasonably priced. It was a huge effort, but it all worked out in the end. I saved $1000s by handling it quickly. Letting go of that particular art studio was a bummer though. I made a lot of art there and was able to handle dirty fabrication and clean tech work in the same space. That’s rare to have.
On a positive note, everything is consolidated and well stored, so when I return I don’t have to deal with my stuff right away. It gives me more options.
Atlanta College of Art reunion
I had never been to any school reunions. They just weren’t something I was very interested in. I’ve definitely visited old friends though and maintaining connections is important to me. While I was planning my trip back to California, I got an invitation to an Atlanta College of Art reunion that covered many years of graduates.
At first, I thought ‘no’ because I was already spending the money on a return to the U.S., but I saw a lot of names of people I hadn’t seen since the mid 90s. All our paths diverged widely and also some were having hard times. Something in my gut said I wouldn’t I see many of them ever again. So, at the last minute I bought a ticket and committed to attending.
Neil Carver with five dollars of fun
It was a mixed experience. Obviously, it was cool to see so many people from a fun time in our lives. But, our stories since then had plenty of struggle. Some of the people we thought would be art stars ended up doing nothing and some we thought were just hanging around did quite well. I see the same upside down trend in younger artists here in Berlin. Also, Atlanta has changed so much. Whatever connection and nostalgia I had for that city has closed. That chapter is done.
I also learned that 2 people I had known well were now dead. There were stories of others on the edge. Sure enough, within 3 months of the reunion, I heard 3 more had died. I won’t get into details for privacy, but it wasn’t from natural causes. We lost some interesting and creative people. That particular group of people from that time, myself included, seem to be connected by a hardship we rarely talked about openly.
Overall, I’m glad I went. I saw some friends I really wanted to keep in touch with, in person. It was crucial to make human contact with friends that had become online avatars. Social media is useful, but it’s not real. I also see our experience in terms of what I’ve learned about art history. The paths of historic artists are not as clean and heroic as we make them out to be. For every artist we remember, there are thousands that didn’t make it into history. But, nonetheless, they had amazingly prolific and creative lives making art.
Supermarket in Stockholm
Supermarket is an international art fair focused on art collectives and artist run spaces. It’s held annually in Stockholm, Sweden to coincide with the more commercial Market Art Fair. I wanted to learn more about how different collectives are managed and run, so I signed up for their Meetings Extended package. That let me attend the fair with access similar to a group exhibitor, but as an individual artist.
I came back thinking I had seen the future. There was a broad range of community organizations. Very little was institutional or connected to a single person. They had formed logistic groups and had access to property and diverse funding sources. Co-operative art groups are nothing new, but the internet absorbed much of the energy people used to put into organizing in person. It was refreshing and inspiring to see so many effective collectives from around the world.
It was especially notable because of the failure I saw at Documenta 15 last year. That famous art festival turned over control to a collective made of other collectives. It was ambitious, but the art was weak and overly dependent on buying into the theoretical and ideological structures they based it on. It offered an example of how collectives don’t work. But, at Supermarket, I had a glimpse of more diverse and structured approaches to collectivism that do work.
I was there for 5 days and learned practical approaches to organizing and met lots of interesting people. When I return to the U.S., I hope to bring that logistical knowledge with me. American art institutions, in so many ways, are collapsing. These collectives are the way forward.
The new lucidbeaming.com
This year, I completely redesigned my website to match how people actually use it. You’re looking at it now.
I’m a member of a local tech art group called Creative Code Berlin. Each month, a variety of people give demos of projects they’re working on and a short presentation. At the end, people post some kind of contact info. Overwhelmingly, people share their Instagram accounts and not much else. A few have dedicated websites, but most depend on Instagram to do the heavy lifting of showing off their work.
That has serious drawbacks. First, it’s a commercial platform with limits on content and it weighs content using a proprietary algorithm. It’s also designed as a feed and not an archive. It’s much more difficult to see historical activity in context. Art is not always made like that. Artists aren’t content machines. We’re human.
It gave me the idea to take the useful aspects of sharing an account link but retaining context and ownership. I simplified the main template to be mobile first and fast-loading. Interactivity is basic and javascript features are limited. People are used to swiping and scrolling static content, so that’s what they get. Not many slideshows or video carousels. Everything is embedded on-page and doesn’t require accounts on external platforms. I even removed Google Analytics and don’t have any personal tracking at all.
It’s been the most effective redesign yet and I still get compliments on how simple it is. Most importantly, I don’t have to depend on Instagram to be my internet presence.
3D scans
My phone has lidar, which is a tiny laser that can be used to make volumetric scans of objects and areas. That means I can make 3D images of lots of things. I used it to scan a variety of sculpture I saw this year. Here is a video with the best results.
Leidkultur at HilbertRaum
I had 5 pieces in a group show here in Berlin, at a gallery called HilbertRaum. I was invited based on the glitch portraits I made last year of problematic sculptures at the Zitadelle. They are fairly political and I’m an American, so I was surprised to get asked to show art about German history at a German gallery.
It was an excellent grouping and the space was well suited for my work. I presented them using transparencies on large light panels. The portraits themselves were detailed, vibrant, and somewhat unsettling. Showing them in a way used in bus stop advertisements was a gamble, but I’m happy with how they turned out.
ICC Berlin
The Internationales Congress Centrum Berlin was built in the 70s as the largest conference center in Europe. It’s a massive facility and looks futuristic and monumental. It never lived up to the hype though and has been closed for many years.
photo from bz-berlin.de
They opened it this year for visitors on just one weekend. I had to reserve time slot weeks ahead of time. I wanted to make some photos inside with my old Polaroid SX-70. I also brought my digital camera and made many 10X layered multiple exposures.
Here is a slideshow…
Berghain Box
I built a kick drum machine out of a cigarette tin. It’s named after a famous dance club in Berlin called Berghain that stays open for days at a time.
Near my apartment is weekly flea market in a place called Mauerpark. It has declined in quality since I moved here, but there are still some vendors that have authentic objects from pre-unification East Germany and Eastern Europe. It also seems to do brisk business in selling the belongings of dead people from retirement homes. The number of very high quality family photo albums is somewhat disturbing.
One of my favorite booths sells old cigarette and tea containers made of metal. The graphic design is classic and the boxes are a handy size. I bought a few to hold small Arduino synthesizers I make. The latest is this drum machine.
It has no patterns, shuffle, or other drum sounds. It only cycles a kick drum endlessly. It has tap for tempo, pitch, timbre, and filter. There is no stop/start. I made it as a machine to sync other instruments to and to drive a techno track. I intend to use it with the Nachtbox effect box I made last year. Used together, the yield is a noisey, glitched out industrial drum collider.
Auschwitz
This September, I visited the Auschwitz concentration camp in Poland. It was something I’ve wanted to do to since I arrived in Germany. It took a while to get the logistics timed right, but things came together in the Fall.
I took this as I was leaving, right before the site closed.
Auschwitz is an important place in human history, not only for what actually happened there but what it represents. During World War II, the Nazi regime of Germany gassed and incinerated 1.1 million people at this site, from 1941-1944. They were overwhelmingly Jewish and most were killed immediately upon arrival. The were told they were being relocated and when they arrived, led into what looked like showers for bathing. Then they were gassed with a range of toxic chemicals. Prisoners at the camp loaded the bodies into nearby ovens and they were cremated. It’s not the only place where this happened, but it is the most notorious and the only one left intact as a memorial and museum.
I knew about about this history and had read plenty about the context. But, I really wanted to see the place for myself. I wanted to know what it felt like to stand on the grounds and see the trees and hear the natural sounds of the area. I also wanted to make drawings of the buildings and interiors, as a way of staying present and focused.
In the morning I took the group tour, which I hated. The people I was with were there for very different reasons. I think most of them just wanted to see the spectacle of it all, like a haunted house. For them, it was one of many places they breezed through while touring Europe or Poland. People took selfies and did video streaming, got bored and talked over important information from the guide. Thankfully, I had another ticket for later that let me roam the grounds independently. That ended up being the most meaningful experience.
One building had 100s of prisoner portraits in the hallways. I made some drawings of a few faces, but wished I had more time to do studies. I discovered that most of the images were made by a Polish photographer who was captured and put to work in the camp. His name was Wilhelm Brasse. When I returned to Berlin I watched a documentary about him and also found an archive of many of the images he took.
I started to make drawings of the prisoners, a few each day after work. I also visited the site of the Wansee Conference. It was the meeting where the practical plans for the elimination of Jews were made. Auschwitz was a direct result of that meeting. I made drawings of the Nazi organizers that were there.
My drawing style is too cartoonish to do justice to these images. I kept drawing anyway because it felt like a constructive way of actually connecting to the individual people in these photographs. Instead of thinking of them as “the Jews”, I though a bit more about what their individual stories might have been. I have no idea what I’ll do with these.
One of the biggest impacts of that visit came when I returned. From landing at the airport to riding subways, I was seeing the Germans next to me differently. I didn’t think they were Nazis. But, I wondered if they were put in that time, in that context, would they have ended up that way? It’s similar to thoughts I had growing up in the Southern U.S. If I had been born in 1850, would I have been a Confederate or had friends in the KKK?
We tend to have these easy conclusions in hindsight, from decided history. It’s very easy to pick the right side of history. I’m skeptical when I hear people make righteous proclamations about what they would have done in historical times. It’s crucial that we continue to reflect on our principles as people and societies, to make sure they continue to come from place inside us that is real and enduring.
A few doors down from my apartment in Berlin are these markers. They indicate the people living there were extracted and sent to Auschwitz, where they died. Markers like this are placed all over Berlin as incorporated history. Reminders that we are all living right where the terror began.
Frieze London
One of my goals while living here was to visit a major international art fair – the kind that gets written about in ArtForum. I considered Art Basel in Switzerland or Frieze London in the United Kingdom, or possibly both.
I picked Frieze London and attended in October. I sort of knew what to expect. Mingling with the global super rich in the heart of London was bizarre and not very revealing. I got the feeling there wasn’t much beyond the obvious there. It was such a contrast to the independent art scene in Berlin and the co-ops of Supermarket in Stockholm.
This was hardcore transactional culture on parade. If you didn’t understand the art it was because you didn’t know the right names or follow the right galleries. Most importantly, you had say it all sucked, because putting down artists and gossiping is the social currency there. I was so far out of my element in that place.
I really tried to walk around and find art to connect to, but it was hard. So much of it was designed to be seen and bought, not felt or resonated with. I’m sure many of those artists had other work that offered that, but not there. The whole place reeked of cocaine sweat and plastic wrap, with breezes of expensive perfumes.
Here are a few pieces I did like.
New work
My own art was pretty scattered and sparse this year. Full-time work and limited space suppressed my creative output. I did find some success, though. I made the best of my small working area and focused on new techniques and mediums that were appropriate for that. That meant works on paper with Polaroid transfers, screen printing, leather collage, drawings, lino prints, and print transfers.
I haven’t done this kind of work in a long time. Sometimes I was pushing too hard to get things “right”. I had to just let go and accept that I was a beginner again when it came to printmaking. I also tried to stay focused on imagery and vibes that are natural to me, instead of imitating something I saw on the internet. That impulse turned out to be the most constructive result. I had a regular activity that pulled from somewhere real within my life.
Upcoming plans
I’ve been here 2 years now. It’s been a visceral experience and I’m not done yet. In the next year, I hope to be in more shows and make more solid connections with other artists and gallerists. That isn’t something that can be forced though. I just need to stay active and engaged. Eventually, I meet the right people for me. That’s the way it’s always been.
At the end of this year, I have begun to think of what my life will be when I return. I have no intention of living as an expat. I’ve met many Americans here and they don’t have lives I want to emulate. This move was always time boxed. I’m going to learn what I can and then return to continue a life in art.
I have some technical projects and more multimedia work that is unfinished. I’m not posting many here, but there are all kinds of tech projects cooking right now. They will probably start to manifest in Spring. That will be a whole new chapter of this experience in Berlin.
Last February, I moved to Berlin, Germany to connect with the global art world and explore new ideas in technology and art. It has been challenging, surprising, and fulfilling.
The move was inspired by a failed California Arts Council grant application. I had planned to use that grant to visit Berlin during some key art festivals. While I was waiting to hear about the application, I spent a lot of time researching Berlin and to make best use of the time that grant would enable.
I didn’t get that grant. The feedback I got from the review was conflicting and confusing, but I didn’t dwell on it. Instead, I made plans to drive across the United States as an art making expedition. That turned out well and I returned to my San Jose art studio to work through multiple bodies of work generated out on the road.
The owner of the house I lived in decided to sell his house and I was looking at options for where to live the next year. Post-Covid Silicon Valley didn’t look very appealing and all my options were very expensive. It dawned on me that I might be able to move to Berlin instead. I had done a lot of research already so I knew where to explore that option. Within a week, I decided to take the gamble.
I started applying for jobs in Berlin and 3 months later, I had one. A month after that, I arrived at Brandenberg airport with a backpack, a laptop, and some clothes. A year has passed since then and the experience has been intense and inspiring.
Impressions
Berlin is a very modern large city. It has a strong public transportation network and diverse civic infrastructure. It has been able to absorb many class and culture imports and offers a strong social support network. Culturally, it has the most active and engaged art audience I ever seen in a city. More than New York.
It is not a skyscraper city, but more spread out into neighborhoods defined by rows and rows of 6 story apartment buildings. Much of the architecture is relatively new. Berlin was heavily bombed in WWII. But, there are integrations of historic places everywhere. The past is not forgotten here.
The late 80s East/West culture and re-integration is still a dominant influence on cultural history. The art scene is steeped in stories of an explosion of culture in the early 90s. But, recent shifts include immigration from Arabic and Global South culture. Also, the internet has diffused many of the cultural silos that defined European regionalism. Many books have been written about all these topics. It’s fascinating to be in the middle of it all.
Berlin Art Sites
One of the first things I did when I arrived was look for art events. There are so many here, it was hard to sift through them all. Specifically, finding galleries showing work I was interested in was a chore. There are over 300 galleries here. Then you have regional institutions on top of that. Going through their websites turned out to be a big hassle. Many weren’t made well and it was a slow process.
I wanted a quick way to look at all of the sites without all the pop-ups and GDPR notices. So, I created a web script that made screenshots of all of them and put the images in a folder. That turned out to be pretty useful and I though others would be interested in the results.
So, I built Berlin Art Websites (berlinartgalleries.de). It uses a tool called Puppeteer to make screenshots of all the websites, each Sunday morning. The results are always up to date and show the latest work on their front pages. It just runs on its own, quietly grabbing the latest from all the galleries around Berlin.
I posted a link to it on Reddit and the response was huge. People seemed to really want something like this.
Artwork
In the past year, I have gone to 1-5 art events a week. I’ve seen the best and worst of what Berlin’s art scene offers. I now have a collection of hundreds of postcards and brochures from the shows. Not sure how I’m going to get them all back to the U.S., actually.
Here is a slideshow of some of the highlights.
190 images in a 15 minute video slideshow, with background music
Art takeaways
Berlin has a strong set of art institutions that are well-funded and staffed. It also attracts legions of fresh art school graduates from around the world. There is a good variety of art in the middle as well.
NFTs were very popular when I arrived and had multiple galleries dedicated to only that kind of work. By the end of Summer, many of them were gone or in decline. The legacy of that is screen based art is everywhere. Even if they don’t show NFTs, many galleries went all-in with video screens. Whole rooms with nothing but screens.
Nostalgia for 1992 is still popular, from the re-unification of East and West Berlin. There were a lot of middle-aged artists doing work that first began then. It was hit and miss though. All nostalgia is like that. It’s an optimized memory and not a real connection. Art needs something more real to survive.
Diaspora art was prominent. There were shows dedicated to the Global South, the Middle East, and Ukraine. It felt like every other independent show had the word “de-colonize” in a curatorial statement. In Kassel, east of Berlin, the spectacular failure of Documenta 15 (organized by a Jakarta art collective) was in all the art media.
Projects
Laser
Finding a useful workspace in Berlin turned out to be more difficult than I thought. Most of art spaces take connections to get in or lots of money. There aren’t as many maker spaces, either. I could only find 3 that were public.
I settled on a smaller lab in north Berlin that was close to a subway stop and hardware store. It’s called Happylab and is focused on hobbyists and some electronic makers. It has a small storage space that ended up being really useful for someone getting around by subway all the time.
Typical of modern maker spaces, they have a laser cutter. I never used one for art and wasn’t sure what I would do with it. But, I ended up exploring a few different directions for lighting and as a drawing tool.
Experiments with designs and fabrication
10X
Using a technique I stumbled onto during my cross-country drive, I’ve continued to make layered abstract photographs. These were made at the Botanischer Garten, Museum für Naturkunde, and Park am Gleisdreieck.
Geist
Germany has a difficult history and has gone to great lengths to incorporate its past into the present, using lessons learned from decades of accountability and scholarship. The Zitadelle is a museum in West Berlin that houses a unique exhibit for this purpose. Throughout the region monuments to problematic past leaders were built from 1849 to 1986. Many of the men they memorialize that had terrible legacies. It includes religious leaders, Prussian military leaders, businessmen, and mythical representations of men in power at the time.
These memorials were getting destroyed and vandalized after re-unification. Archivists and historians were left with a dilemma, how to preserve these artifacts without perpetuating the cultural impact they were intended for. They decided to move them all to a central location at a side gallery at the Zitadelle. There they are presented without pedestals or plaques, living on in anonymity and stripped of iconography.
Due to the political upheavals in the 20th century, monuments that represented problematic or even threatening reminders or appreciation of the old ways were removed from public spaces by the new governments. The museum offers an opportunity to come to terms with the great symbols of the German Empire, the Weimar Republic, National Socialism and the GDR, which were supposed to be buried and forgotten – and now serve a new function as testimonies to German history. Instead of commanding reverence, they make historical events tangible in the truest sense of the word.
Unveiled – Zitadelle Museum
“Unveiled. Berlin and its monuments” – Zitadelle Museum
I think that’s a fascinating and powerful solution that can be explored in the United States for our monumental legacy throughout the South.
I photographed the faces and decided to re-contextualize their appearances. In the past decade social media has resurrected some of the worst ideologies in history. They were dying out until anonymous politics became a thing and rekindled their popularity. My idea is to use these statues to build illustrations of these old dying ideas that are empowered by online culture.
Different steps to create a vector mask
Video
I brought an archive of multimedia files I have created over the years. I thought it would be useful, in the absence of a proper fabrication space, to have some computer based art projects to work on. I also shot some new video footage and got certified to fly my drone in the E.U.
Here is a piece I made using time-lapse footage at a famous subway stop called Alexanderplatz:
This abstract video is made from drone footage over Nevada salt flats:
The most recent work combines drone footage from a decommissioned airport with a generative computer art tool called Primitive:
NachtBox
Finished assembly connected to recorder
Back in the U.S. I go to thrift stores fairly regularly. I look for small obsolete electronics I can repurpose and dated hardware to build sculptures around. I tried the same here, but most of the thrift stores are focused on clothing. Buying 2nd hand clothing in Europe and reselling it online is a huge underground business.
I did find a place run buy the recycling agency, called NochMall. It’s grossly overpriced but is a source of occasional treasure for electronic art making.
There I found a micro cassette recorder that a German man had used to record himself playing guitar with TV shows in the background. That tape was the real gold. I decided to use it as the core of a music machine that played the tape through a variety of effects. It turned out to be a long-term complex project.
I chose a Teensy 4.1 micro-controller as the main engine for processing the audio. Besides being fast and having decent memory, the manufacturer has an excellent audio library to make use of. It allowed me to prototype very quickly and get to the noise making steps fast. I’m pretty stoked on how this turned out and look forward to performing with it soon.
Next year
I plan on staying in Berlin for at least another 2 years. I have been paying rent on my San Jose art studio, hoping to return to it when I finish my experience here. Unfortunately, problems with the landlord are forcing me to let go of that work space and move everything into storage. It has been a difficult and expensive conclusion to that place.
However, I feel like I am just getting to know this city. This first year has been interesting, but it feels like I’ve just seen the surface. I’m looking forward to getting to know more artists and gallery folks, as well as the creative coding community. After all, it’s the people that define a community, not just the place.
The language of art reviews can be enigmatic, dense, and obtuse. It can also be complete bullshit.
I read a lot of modern art reviews and have researched historical reviews to get a sense of how art was received over time. A lot of what we consider classic or masterpieces were panned or ignored when they debuted. A great example of this is Vincent Van Gogh. He got no respect for his art while alive and producing, but years later he is lionized in art history books.
Cultural criticism is tricky. It is a whole genre of writing unto itself. Beyond just an opinion, it has to provide context and some kind of grounding for a reader to connect with. Recent (past 50 years) art criticism is deep in theory and analytic constructs. When done well, it can be enlightening and useful. At its worst, it’s a bunch of made up gibberish with strategic name dropping and references to better thinkers.
I took 50+ years of art criticism from a famous art magazine and trained a GPT-2 language model with it. I thought it could be an interesting tool to analyze trends and patterns in cultural language. It absolutely serves as that, but it can also be fun to feed it prompts and see what it comes up with. It generates reviews word by word, algorithmicly, not randomly or by using real reviews.
I have a show of tech art that will be coming down soon and thought it would be interesting to see what kind of review the generator would give me. I came up with some probable ledes that a reviewer might start with and finished with a fully automated approach. The results were fascinating and sometimes insightful.
The actual show, Refactor
I have a small grouping of tech art at a local gallery called Kaleid in San Jose, CA. It ranges from glitch art on a recycled screen to a wind driven interactive piece that simulates embers of a fire.
The reviews are in…
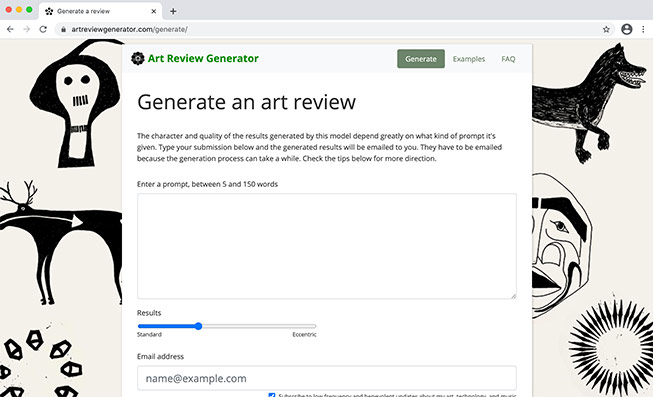
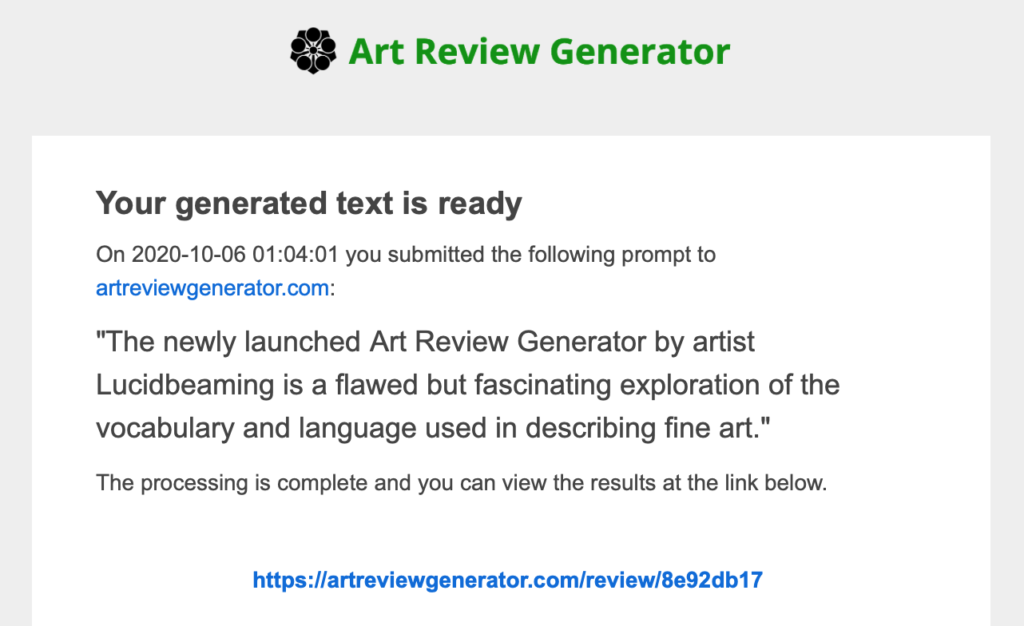
The tool I built is called Art Review Generator and accepts a text prompt of 5 to 150 words to generate an art review from. I wrote a detailed blog post about the creation of that a few months ago. It returns 5 reviews for each prompt, along with a permanent link to the results.
I started out traditionally:
A recent show of tech art by Lucidbeaming explores a range of humanistic themes, from aging to social collaboration. The combination of glitching screens and traditional materials is disarming and intriguing. Ultimately, the verdict is
is in the artists hands. But the question remains: Are the tech art works entertaining? There’s a particularly sexy, sexy quality to the flow of the world through which we travel.
still to be made. Is it a medium to engage in a serious conversation about the nature of art? Or a more passive form of entertainment? The answer is a resounding no. Lucidbeaming is a truly inspiring endeavor.
out. Its a satisfying show.
Well, that’s positive and weirdly flirtatious. Let’s try something more descriptive.
Using found materials and modern electronics, San Jose artist Lucidbeaming has created a wide range of interactive sculpture that ultimately
lends itself to a range of social and cultural meaning. The artists early work was performed by groups of people who were not intended to be fully autonomous. He uses found objects and found images to address specific social issues, such as the fear of violence in the face of poverty, and the challenges of belonging in a world that has changed. In a series of photographs, San Jose’s Department of Public Safety has been forced to submit to a government-sanctioned request to provide police officers with body cameras.
ices over any attempt to resolve the conceptual conflict between art and technology. The works are accompanied by a text, a video, and an audio tape.
Interesting contrast of references. How about something more ambivalent?
Teetering on the edge of spectacle and genuine artistic exploration, the latest show of multimedia art at Kaleid Gallery is
ersatz. Despite the apparent naïveté of its premise, the show is, as its title suggests, structured to attract attention. Using the most avant-garde of means—including the cinema of projection, video, and sound installations, as well as photography, drawing, and painting—Kaleid invites the spectator to enter his or her own private cinema of projection. It is a movie theater, an enclosed gallery, and an exhibition space, each with its own subjective and critical boundaries.
ersatz—albeit masterfully botched. Its not the smart thing to do, either. Instead, the show should be seen as an alternative to the years of febrile art-world machismo—the years of art school put on by young artists, like the artist/curator of this show, Tomoko Murakami, and the late, great Noguchi—and as an attempt to correct the balance between the deadpan and the smart.
This generator loves the words “ersatz” and “vernacular”. Let’s try a combination of detail and context.
Refactor is a small show of recent interactive and video art by San Jose artist Lucidbeaming. It combines found materials with high tech sensors and medium sized computer screens. Titles such as Obsolete, Tintype, and Embers evoke nostalgic and humanist connections. But, buried under the veneer of glitchy techniques are problematic
vernaculars that are at odds with the technical sophistication of the works. The works range from the modest to the whimsical. One piece is a video projection of a woman dancing, a half-naked woman with a plastic bag over her head, a red ball on her head and a green one on her hand. The video is looped and the video is repeated ad infinitum, as if the video were a dance. Another piece consists of a video of a woman using a large-brimmed hat as a mask and a small video monitor that shows the person using the hat as a mask. The hat is a toy, a projection of a toy, and the video is looped, making the hat a puppet. In one of the videos, a woman uses a small screen to make a face. Her face is a puppet, and the video is looped, making the face a puppet. The video is looped so that the face turns into that of the woman who is using the hat as a mask. The video is looped so that the woman becomes a puppet, and the video is looped so that the woman becomes a puppet. The puppet becomes a projection of the woman using the hat as a mask. The video is looped so that the hat becomes a projection of the woman using the hat as a mask. The hat becomes a projection of the woman using the hat as a mask. The video is looped so that the hat becomes a projection of the woman using the hat as a mask. The hat becomes a projection of the woman using the hat as a mask. The video is looped so that the hat becomes a projection of the woman using the hat as a mask. The hat becomes a projection of the woman using the hat as a mask. The video is looped so that the hat becomes a projection of the woman using the hat as a mask. The hat becomes a projection of the woman using the hat as a mask.
There’s that word “vernacular”. Not a very coherent review, but I really want to see the video it’s describing get made. So how about something really negative?
A pointless and derivative show of so called “glitch art” is thankfully ending soon at Kaleid Gallery in downtown San Jose. Besides the low quality execution and realization, the work itself is crushingly obtuse and fake.
It’s like the material evidence of a murder, but done with a look of a cop-out. The art world is catching up to the curve, and the police are finding their quarry. The police are also catching up to the curve, but this time they’re using a more sophisticated approach to their quarry, they’re making a mistake. The artists are being followed, photographed, photographed, photographed and photographed again. The art world is being used as bait and trap, a game of game-show host, playing the game of deception. The artists are being followed by the police. In the end, its all a game of distraction. The police are using the art world as a trap, and they’re winning.
The show has been subjected to a highly effective and lucrative critique by Leonard Bernstein, who has written of the art-world hypocrisy of hoping that something will change. In his recent essay for the catalogue, Bernstein continues to work against art, saying that he hopes to see art that is just as useful and important as other kinds of things, but not so easy to get and use. His hope is that such a thing will happen.
It is a failure to consider the problem of artistic glitch art. The work is often sloppy, overworked, and often perfunctory, and it does not relate to any real conceptual or esthetic problems. The work is often a combination of high art and low art, an art that is neither art nor a thing. The work is usually poor, and yet it is an art of low quality, a low art. This is a shame, for it is a shame that is so obviously, and intentionally, wrong. The work is often amateurish, and yet it is not amateurish, for the work is an art of high quality, and its subject is art.
Wow, more police references. Probably because it used the phrase “cop-out”. These aren’t as biting as I hoped. I doubt there were as many truly negative reviews as legend describes. Now, time for some name dropping theory.
Marxist historian Eric Hobshawm argued that the technology of cinema had superceded anything traditional art could accomplish. The latest show of multimedia art by Joshua Curry at Kaleid gallery tempts fate by
turning into the opposite category: the art of the artist as mere instrument. Curry has never been quite as daring as he once was; his works are sometimes too clever and too sly. But he is still able to make you laugh, and you’ll be happy to see him again.Curry is a video artist who knows the difference between illusion and reality, and he knows the difference between the real and the artificial. He knows that the real is always a lie, but he cant be too precise. He also knows that the artificial is always a lie, but he can’t be too precise. Curry shows us the limits of the lies he tells, and he has the nerve to call attention to them. His work has always been ambitious and deeply ironic, but it is not cynical. He knows that the lie of art lies in the capacity to tell the truth, but he doesn’t take the risk of being too strict. He has been the first to call attention to the problems of the lie of art. He knows that art, like a lie, can be a tool of power and that it can be used to control people and to exploit them. He knows that the lies it tells are a lie, but he doesn’t care. He knows that when art is used as a tool of power it can be used to control the public, and that it can be used to exploit people. He knows that art is a lie, but he doesn’t give a damn.
turning art to offer a simulacrum of the non-art world. Curry has often sought to redefine non-art via his performances (often choreographed by the artist), which use space and language as interactive agents in which the viewer becomes part of a narrative and/or nonhuman system of transmission. A video installation with its accompanying text, Transmission: A Conversation with Maia in 21 Photos, 2017–18, plays out the techniques and cultural norms of the viewer through the processes of transmission itself. Each of the 21 shots is projected onto a wall of the gallery, and these texts can be read as a text for the installation itself: AN EXHIBITION, THE BOXER IN MEAN TIME, ARISTOTHEI, OBSERVATION, CONVERSATION, DISCO, PERCEPTION, PROJECTION. The texts are constructed from a series of mirror images of various letters, including a list of things a person looks at when she ponders about a text, words of utterance such as HOW DID I NOT KNOW IT WAS THE POWER OF GOD, AND HOW DID I NOT KNOW IT WAS THE POWER OF FAULTY, AND WHAT IF YOU DON’T LIKE IT?
That first one is pretty good, even with the insult. But that second one — I want to go to whatever show that is.
How about fully automated? I used an image auto-tagging service called Imagga to yield descriptive words of the photos of my work in the show. Then I ran those tags through as a prompt. This is getting close to submitting images of an art show and getting an automatic review in return. That’s a possible future project. But, let’s see if it works.
The show by Lucidbeaming has frame, binding, furniture, interior, room, home theater, theater, building, petal, wall clock, clock, timepiece, monitor, and liquid crystal display.
There’s a big box of Legos, a box of chess pieces, a small refrigerator, and a drawer filled with all manner of knickknacks. There’s a portable, wooden crucifix with the word sinet. A set of 14 vintage televisions—one for each year of the show—possess individual CRT monitors. There’s a wooden box with a radio and a cassette deck. There’s a small, semitransparent plastic case. Its the one-half of a cross. A real crucifix—topped with a heart—and a mirror. There’s a gray box filled with money. A heart is carved into the back of the case. There’s a picture of the gallery space with a big white cross.
It is not a conventional presentation; rather, it is an exhibition of the moments that shaped Lucidbeaming as a person, and that have shaped his art. At the same time, Lucidbeaming does not present a conventional display of his art; rather, it is a display of the moments that have shaped his life. Perhaps this is why Lucidbeaming has become a favorite of critics and artists. In his interviews, he has spoken of his appreciation for the importance of the past and of the ephemeral nature of the past. His work is much more than the sum of his words; it is a microcosm of the past, a time capsule, a chronicle of the artists relationship to the city and to himself. His work is not only about the past, it is also about the present, an exhibition of the present that can be read or studied. And it is not about a mise-en-scène, its a display of the present.
Its a vast, dizzying, dizzying show—just what you need to get in the morning, and as long as you are a morning person. The show was set to run through the evening, and Lucidbeaming even built a wall of mirrors in the gallery, from which a tape played on loop, a reminder that you would be well advised to visit this show early in the morning. Of course, the exhibition is not over yet: a dozen or so artists have offered more shows—shows, in other words, that the eye will never get to seeing. Lucidbeaming has responded with an admirable, lighthearted, and entirely unpretentious installation. His artistic is such that it becomes the most direct and persuasive form of communication—and a possible new form of communication for art as well. Lucidbeaming is not as profound as some of his colleagues, but he is a capable artist who will keep on working in a lighthearted, humorless, and irreverent vein. He is also a very American man.
The tags were not very accurate but these reviews are pretty good. Different services from Google or Amazon would probably nail the tagging effectively, but I avoid their ecosystems.
“Lighthearted, humorless, and irreverant” is awkwardly accurate. I might start using it my insta bio.
I spent most of the year in my art studio while the city around me contracted and calcified due to Covid. I was fortunate that my plans coincided with the timing and degree of changes in the world. It could have very easily gone the other way, as I’ve seen firsthand. Lots of my friends in the art community are struggling.
My work this year reflects more studio and internet based processes. Previous years always included public festivals, performances, and collaborations. Some of that change was to save money, but it was also an effort to make use of what I had around me. It was to stay present and maintain momentum with ongoing projects.
I did actually manage to pull off a few public projects, including a portable projection piece that had animated wolves running on rooftops. I savored that experience and learned a lot from the constraints of lock-down art performances.
Looking back on this year, I see new priorities being formed. While the coding and online projects were effective, the amount of screen time required took a toll. I relished the drawing projects I had and hope to keep working in ways that make a huge mess.
Sightwise
My studio complex has a co-op of artists called FUSE Presents. We hold regular group art shows in normal times and for each show, two artists get featured. I was one of the featured artists for the March 2020 show. That meant I got extra gallery space and special mention in marketing materials.
The work I picked was drawn from a variety of efforts in the previous two years. As a grouping, it represented my current best efforts as a multimedia artist. I worked hard to finalize all the projects and really looked forward to the show.
It combined abstract video, traditional photography, sculptural video projection, installation work, and works on paper.
I designed the show’s poster in open source software called Inkscape. A highlight of the show was watching this little girl react to some abstract videos I made.From the Grounded series of high contrast monochromatic photographsFrom the Grounded series of high contrast monochromatic photographsLayered macro videos projected in seriesDelphiFrom the Redacted series of modified book pagesEnlarged Polaroid of a TV screen showing a still from Smokey and the BanditGrounded, Snowman, Bad LiarFrom the Redacted series of modified book pagesMade to show 96 glitch videos, this piece is called TintypeFound wood encasing a Kindle tablet, showing the videos from SpannerRedacted, GroundedUnclaimed AshesGrounded, SnowmanWood tablet, TintypeEarly version of Bad Liar (see below)
Unfortunately, the show happened right as the first announcements about the local spread of Covid had begun. People were already quarantined and we heard about the first deaths in our county. That news didn’t exactly motivate people to come out to the art show. Attendance was sparse at best. But, all that work is finished now and ready for future exhibits.
Camel
I found a cigarette tin that had been used as a drug paraphernalia box and decided to build a synthesizer out of it. I had been experimenting with a sound synthesis library called Mozzi and was ready to make a standalone instrument with it. I spent about a month on the fabrication and added a built-in speaker and battery case to make it portable. Sounds pretty rad.
The finished instrumentConnecting the controls to an internal Arduino and speakerEarly assembly and fabricationA fan in Vienna, Austria recreated my synth using a cake box
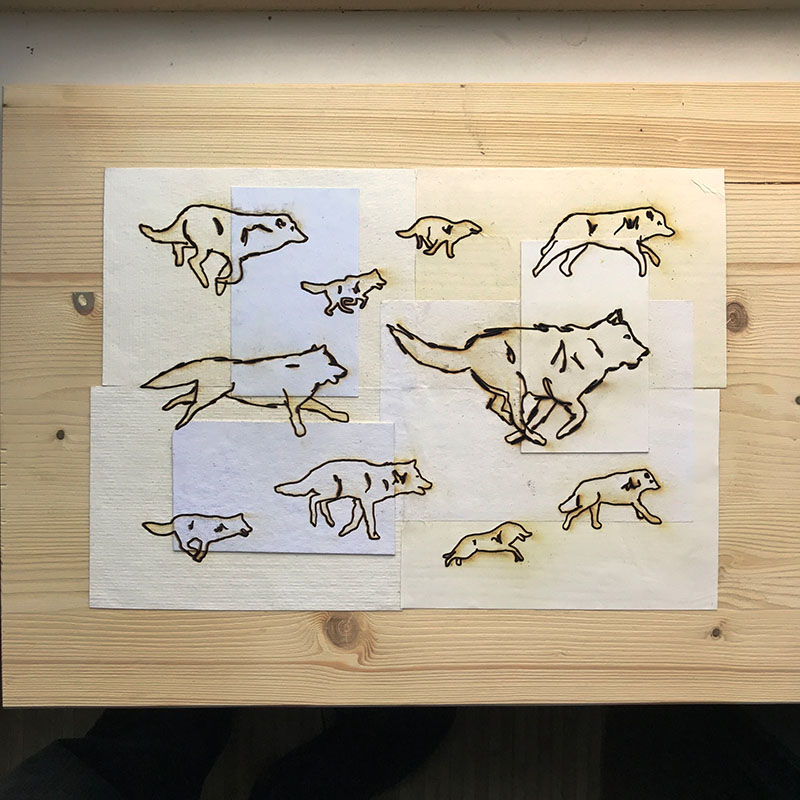
The Wolves project was a major undertaking that took place over 2 years. It began with an interest in the Chernobyl wolves that became a whole genre of art for me.
I began hand digitizing running wolves from video footage and spent a year adding to that collection. I produced hundreds and hundreds of hand drawn SVG frames and wrote some javascript that animated those frames in a variety of ways. I got to the point where I could run a Raspberry Pi and a static video projector with the wolves running on it. I took a break from the project after that.
By the time I returned to the project, the Covid lockdown was in full swing and American city streets looked abandoned. We all started seeing footage of animals wandering into urban areas. It made sense to finish the Wolves project as an urban performance, projecting onto buildings from empty streets.
Building a stable, self-powered and portable rig that could be pulled by bicycle turned out to be harder than I thought. There were so many details and technical issues that I hadn’t imagined. Every time I thought I was a few days from launch, I would have to rebuild something that added weeks.
The first real ride with this through Japantown in northern San Jose was glorious. Absolutely worth the effort. I ended up taking it out on the town many times in the months to come.
Truck battery and inverterBike hitchRight projector lensLeft projector lensPower up test in the backyardSan José City HallJapantown, north of downtown San José
The above video is from Halloween, which was amazing because so people were outside walking around. That’s when the most people got to see it in the wild.
But, my favorite moment was taking it out during a power blackout. Whole neighborhoods were dark, except for me and my wolves. I rode by one house where a bunch of kids lived and the family was out in the yard with flashlights. The kids saw my wolves and went crazy, running after them and making wolf howl sounds while the parents laughed. Absolute highlight of the year.
Videogrep
Videogrep is a tool to make video mashups from the time markers in closed captioning files. It’s the kind of thing where you can take a politician’s speech and make him/her say whatever you want by rearranging the parts where they say specific words. It was a novelty in the mid-2000s that was seen on talk shows and such, as a joke. Well, the computer process behind the tool is very useful.
I didn’t create videogrep, Sam Lavigne did and released his code on Github. (BTW, the term “grep” in videogrep comes from a Unix utility (grep) used to search for things) What I did do is use it to find other things besides words, such as breathing noises and partial words. I used videogrep to accentuate mistakes and sound glitches as much as standalone speech and words.
Below is a stretched supercut of the public domain Orson Welles movie The Stranger. I had videogrep search for sounds that were similar to speech but not actual words or language. Below that clip is a search of a bunch of 70s employee training films for the word “blue”. Last is a supercut of one the Trump/Biden debates where the words “football and “racist” are juxtaposed.
Specific repeated words used in a 2020 Presidential Debate: fear, racist, and football
Vid2midi
While working on the videos produced by videogrep, I found a need for soundtracks that were timed to jumps in image sequences. After some experimenting with OpenCV and Python, I found a way to map various image characteristics to musical notation.
I ended up producing a standalone command-line utility called vid2midi that converts videos into MIDI files. The MIDI file can be used in most music software to play instruments and sounds in time with the video. Thus, the problem of mapping music to image changes was solved.
The video above was made with a macro lens on a DSLR and processed with a variety of video tools I use. The soundtrack is controlled by a MIDI file produced by vid2midi.
Bad Liar
This project was originally conceived as a huge smartphone made from a repurposed big screen TV. The idea is that our phones reflect our selves back to use, but as lies.
It evolved into an actual mirror after seeing a “smart mirror” in some movie. The information in the readout scrolling across the bottom simulates a stock market ticker. Except, this is a stock market for emotions. The mirror is measuring your varying emotional states and selling them to network buyers in a simulated commodities exchange.
Outer frame gluingScreen testingBack assemblyMedium viewScreen test showing emotional stock marketFinal demo in the studio
Hard Music in Hard Times
TQ zine is an underground experimental music zine from the U.K. I subscribed a few years ago after reading a seminal essay about the “No audience underground”. I look forward to it each month because it’s unpretentious and weird.
They ran an essay contest back in May and I was one of the winners! My prize was a collection of PCBs to use in making modular synthesizers. I plan to turn an old metal lunchbox into a synth with what I received.
I spent much of my earlier art career as a documentary photographer. I still make photographs but the intent and subject matter have changed. I’m proud of the photography I made throughout the years and want to find good homes for those projects.
Last year I went to the SF Art Book Fair and was inspired by all the publishers and artists. Lots of really interesting work is still being produced in book form.
Before Covid, I had plans to make mockups of books of my photographs and bring them to this year’s book fair to find a publisher. Of course, the fair was cancelled. I took the opportunity to do the pre-production work anyway. Laying out a book is time consuming and represents a standalone art object in itself.
I chose two existing projects and one new one. American Way is a collection of photos I made during a 3 month American road trip back in 2003. Allez La Ville gathers the best images I made in Haiti while teaching there in 2011-13 and returning in 2016. The most recent, Irrealism, is a folio of computer generated “photographs” I made using a GAN tool.
It was a thrill to hold these books in my hands and look through them, even if they are just mockups. After all these years, I still want my photos to exist in book form in some way.
Allez La Ville, American Way, IrrealismAmerican Way coverAmerican Way title pageAmerican Way insideAmerican Way insideAmerican Way insideAllez La Ville coverAllez La Ville title pageAllez La Ville insideAllez La Ville insideAllez La Ville insideIrrealism coverIrrealism insideIrrealism insideIrrealism inside
Art Review Generator
Working on the images for the Irrealism book mentioned above took me down a rabbit hole into the world of machine learning and generative art. I know people who only focus on this now and I can understand why. There is so much power and potential available from modern creative computing tools. That can be good and bad though. I have also seen a lot of mediocre work cloaked in theory and bullshit.
I gained an understanding of generative adversarial networks (GAN) and the basics of setting up Linux boxes for machine learning with Tensorflow and PyTorch. I also learned why the research into ML and artificial intelligence is concentrated at tech companies and universities. It’s insanely expensive!
My work is absolutely on a shoestring budget. I buy old computer screens from thrift stores. I don’t have the resources to set up cloud compute instances with stacked GPU configurations. I have spent a lot of time trying to figure out how to carve a workflow from free tiers and cheap hardware. It ain’t easy.
One helpful resource is Google Collab. It lets “researchers” exchange workbooks with executable code. It also offers free GPU usage (for now, anyway). That’s crucial for any machine learning project.
When I was laying out the Irrealism book, I wanted to use a computer generated text introduction. But, the text generation tools available online weren’t specialized enough to produce “artspeak”. So, I had the idea to build my own art language generator.
The short story is that I accessed 57 years of art reviews from ArtForum magazine and trained a GPT-2 language model with the results. Then I built a web app that generates art reviews using that model, combined with user input. Art Review Generator was born.
This really was a huge project and if you’re interested in the long story, I wrote it up as a blog post a few months ago. See link below.
Video as art can be tricky to present. I’m not always a fan of the little theaters museums create to isolate viewers. But, watching videos online can be really limited in fidelity of image or sound. Projection is usually limited by ambient light.
I got the idea for this from some advertising signage. It was seeded with a monitor donation (thanks Julie Meridian!) and anchored with a surplus server rack I bought. The killer feature is the audio level rises and falls depending on whether is someone is standing in front of it or not. That way, all my noise and glitch soundtracks aren’t at top volume all the time.
This plays 16 carefully selected videos in a loop and runs autonomously. No remote control or start and stop controls. Currently installed at Kaleid Gallery in downtown San Jose, CA.
Ultrasonic distance sensorsUpper screen and speakersAuto-updating e-ink displayFinal assembly in the studioDelivered to Kaleid gallery
Holding the Moment
Hanging out in baggage claim with no baggage or even a flight to catch
In July, the San José Office of Cultural Affairs announced a call for submissions for a public art project called Holding the Moment. The goal was to showcase local artists at Norman Y. Mineta San José International Airport.
COVID-19 changed lives everywhere — locally, nationally, and internationally. The Arts, and individual artists, are among those most severely impacted. In response, the City of San José’s Public Art Program partnered with the Norman Y. Mineta San José International Airport to offer local artists an opportunity to reflect, comment, and on of this global crisis and the current challenging time. More than 327 submissions were received, and juried by a prominent panel of Bay Area artists and arts professionals. Ultimately 96 artworks by 77 San José artists were awarded a $2,500 prize and a place in this six-month exhibition.
SAN JOSE OFFICE OF CULTURAL AFFAIRS
Two of my artworks were chosen for this show and they are on display at the airport until January 9. They picked some challenging pieces, PPE and Mask collage, with interesting back stories of their own.
Left display caseLobby viewRight display caseCloser to the mask collage
Here are the stories of the two pieces they chose for exhibition.
PPE
The tale of this image begins in Summer of 1998. I had a newspaper job in Louisiana that went badly. One of the few consolations was a box of photography supplies I was able to take with me. In that box was a 100′ bulk roll of Ilford HP5+ black and white film. My next job happened to involve teaching digital photography so I stored that bulk roll, unopened and unused, for decades. I kept it while I moved often, always thinking there would be some project where I would need a lot of black and white film.
Earlier this year, I was inspired to buy an old Nikon FE2 to make some photos with. I just wanted to do some street photography. After Covid there weren’t many people in the streets to make photos of. But, I did break out that HP5+ that I kept for decades and loaded it onto cassettes for use in the camera I had bought. I also pulled out a Russian Zenitar 16mm f2.8 that I used to shoot skateboarding with.
This past Summer, I went to Alviso Marina County Park often. It’s a large waterfront park near my house that has access to the very bottom of San Francisco bay. People would wear masks out in the park and I even brought one with me. It was absolutely alien to wear protective gear out in a huge expanse like that.
So, my idea was to make a photo that represented that feeling. I brought my FE2 with the old film and Zenitar fisheye to the park, along with a photo buddy to actually press the button. People walking by were weirded out by the outfit, but that’s kind of the desired effect.
This image was enlarged and installed in the right-hand cabinet at the airport show.
Bulk film and loader with cassettes from 1998Going through pages of negatives for the first time in over 15 yearsFilm can re-purposed as noise controllerFilm can re-purposed as noise controller
An interesting side note to this project was recycling the can that the old film came in. Nowadays that would be made of plastic but they still shipped bulk film in metal cans back then. I took that can and added some knobs and switches to control a glitching noisemaker I had built last year. So, that old film can is now in use as a musical instrument.
The film can that used to hold 100′ of Ilford HP5+ is now a glitch sound machine
Mask Collage
Face masks are a part of life now but a lot of people are really pissed that they have to wear them. I was in the parking lot of a grocery store and a guy in front of me was talking to himself, angry about masks. Turns out he was warming up to argue with the security guard and then the manager. While I was inside shopping (~20 minutes) he spent the whole time arguing loudly with the manager. It was amazing to me how someone could waste that much time with that kind of energy.
When I got back to my studio I decided to draw a picture of that guy in my sketchbook. That kicked off a whole series of drawings over the next month.
I have a box of different kinds of paper I have kept for art projects since the early 90s. In there was a gift from an old roommate: a stack of blank blood test forms. I used those forms as the backgrounds for all the drawings. Yellow and red spray ink from an art colleague who moved away provided the context and emotional twists.
The main image is actually a collage of 23 separate drawings. It was enlarged and installed in the left-hand cabinet at the airport show.
Angry anti-maskerMixed feelings about masksThe guy that won’t wear it rightThe politician
Internet Archive
A few weeks ago, my video Danse des Aliénés won 1st place in the Internet Archive Public Domain Day film contest. It was made entirely from music and films released in 1925.
Danse Macabre Op. 40 Pt 1 (Dance of Death) Camille Saint-Saëns Performed by the Philadelphia Symphony Orchestra
Danse Macabre Op. 40 Pt 2 (Dance of Death) Camille Saint-Saëns Performed by the Philadelphia Symphony Orchestra
Plans? What plans?
Vaccines are on the way. Hopefully, we’ll see widespread distribution in the next few months. Until then, I’ll still be in my studio working on weird tech art and staying away from angry mask people.
I am focused on future projects that involve a lot of public participation and interactivity. I think we will need new ways of re-socializing and I want to be a part of positive efforts in that direction.
I also have plans for a long road trip from California to the east coast and back again. It will be a chance to rethink the classic American photo project and find new ways to see. But, that depends on how things work out with nature’s plans.
This is a long blog post. I included many details that were part of the decision process at each phase. If you are looking for a concise tech explainer, try this post instead.
I recently published a book of computer generated photographs and wanted to also generate the introductory text for it. I looked around for an online text generator that lived up to the AI hype, but they were mostly academic or limited demos. I also wanted a tool that would yield language specific to art and culture. It didn’t exist, so I built it.
My first impulse was to make use of an NVIDIA Jetson Nano that I had bought to do GAN video production. I had spent a few months trying to get that up and running but got frustrated with dependency hell. I pulled it back out and started from scratch using recent library updates from NVIDIA.
Long story short; it was a failure. Getting that little GPU machine running with modern PyTorch and Tensorflow was a huge ordeal and it is just too under-powered. Specifically, 4gb of RAM isn’t enough to load even basic models for manipulation. I was asking much more from it than the design intent, but was hoping it was hackable. Nope.
The breakthrough came while I was digging around the community for Huggingface.co tutorials that focused on deploying language models. Somebody recommended a Google Collab notebook by Max Woolf that simplified the training process. I discovered that Google Collab is not only a free service, it allows use of attached GPU contexts for use in scripts. That’s a big deal because online GPU resources can be expensive and complicated to set up.
In learning to use that notebook I realized I needed a large dataset to train the GPT-2 language model in the kind of writing I wanted it to produce. A few years ago I had bought a subscription to ArtForum magazine in order to read through the archives. I was, and still am, interested in the art criticism of the 60s and 70s because so much of it came from disciplined and strong voices. Art criticism was still a big deal back then and taken very seriously.
I went back to the ArtForum website and found the archives were complete back to 1963 and presented with a very consistent template system. Some basic web scraping could yield the data I needed.
Scraping with Python into an SQLite3 database
The first thing I did was pay for access to the archive. It was worth the price and I got a subscription to the magazine itself. Everything I did after that was as a logged in user, so nothing too sneaky here.
I used Python with the Requests and Beautiful Soup libraries to craft the scraping code. There are many tutorials for web scraping out there, so I won’t get too detailed here.
I realized there might be circuit breaker and automated filtering on the server, so I took steps to avoid hitting those. First I rotated the User Agent headers to avoid fingerprinting and I also used a VPN proxy to request from different IP addresses. Additionally, I put a random delay ~1 second between requests so it didn’t hammer the server. That was probably more generous that it needed to be, but I wanted the script to run unattended so I erred on the side of caution. There was no real hurry.
headers_list = [
# iphone
{
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-us",
"Connection": "keep-alive",
"Accept-Encoding": "br, gzip, deflate",
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_1_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.1 Mobile/15E148 Safari/604.1"
},
# ipad
{
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-us",
"Connection": "keep-alive",
"Accept-Encoding": "br, gzip, deflate",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.1 Safari/605.1.15"
},
# mac chrome
{
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-us",
"Connection": "keep-alive",
"Accept-Encoding": "br, gzip, deflate",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36"
},
# mac firefox
{
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-us",
"Connection": "keep-alive",
"Accept-Encoding": "br, gzip, deflate",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:70.0) Gecko/20100101 Firefox/70.0"
}
]
This was a 2 part process. The first was a script that collected all the links in the archive from the archive landing page, grouped by decade. The larger part was next, requesting all 21,304 links collected and isolating the text within.
for x in range(1, quantity):
if (x == 1) or ((x % 10) == 0):
proxy = random.choice(proxies)
headers = random.choice(headers_list)
sesh.headers = headers
sleep(random.uniform(.5, 1.5))
URL = links[x][0]
page = sesh.get(URL, proxies=proxy)
soup = BeautifulSoup(page.content, 'html.parser')
h1 = soup.find_all('h1', class_='reviews__h1')
body = soup.find_all('section', class_='review__content')
date = URL[39:43]
title = " ".join(str(h1[0].text).split())
text = " ".join(str(body[0].text).split())
text = text.replace(u"\u2018", "").replace(u"\u2019", "").replace(u"\u201c","").replace(u"\u201d", "")
try:
cursor.execute("INSERT INTO reviews(date,title,text) VALUES (?,?,?)", (date,title,text))
except sqlite3.Error as error:
print("Failed to insert", error)
Once all the reviews were collected, I ran some cleaning queries and regex to get rid of punctuation. Then it was a simple export to produce a CSV file from the database.
Training the GPT-2 model
Now that I had a large collection of language examples to work with, it was time to feed the language model. This stage requires the most compute power out of any part of the project. It also makes use of specialized libraries that run most efficiently with a GPU. On a typical desktop computer system, the GPU is usually the video card and comes from a variety of vendors.
Last decade, the rise of cryptocurrency mining absorbed large stocks of GPU hardware. People built huge GPU farms to generate this new virtual gold. That drove innovation and research capital in the GPU manufacturing market. Modern machine learning and neural network implementation reap the benefits of that fast progress.
In academic and corporate environments, custom onsite infrastructure is an option. For smaller businesses, startups, and independent developers, that can be cost prohibitive. What has evolved is a new GPU provisioning economy. In some ways it’s a throwback to the mainframe timeshare ecosystems of the 70s. Full circle.
For this project, my budget was zero. GPU attached server instances come at a premium starting at $.50/hr. ($360 a month). So, I looked into all kinds of free tiers and promotional servers. I even asked around at Grey Area hoping some alpha geek had her own GPU cluster she was willing to share. No dice.
What I did find was a Tensorflow training tutorial using Google Colab, which offers FREE GPU compute time as part of the service. I didn’t know about Colab, but I had heard plenty about Jupyter notebooks from former co-workers. They are sharable research notebooks that can run code. Jupyter depends on the underlying capabilities of the host machine. Google has vast resources available, so their notebook service include GPU capability.
The tutorial is straightforward and easy. After months of wrestling the Jetson Nano into a stalemate, watching Collab load Tensorflow and connect to my CSV so fast was shocking. I successfully had simple training working in less than an hour. Generated text was only a few minutes later. I was in business.
There are a few options for the training function and I spent some time researching what they meant and tinkering. The only option that had relevant effect was the number of training steps, with a default of 1000.
I had interesting results at 200 training steps, good results at 1000, better at 5000 steps. I took that to mean more is always better, which is not true. I ended up training for 20000 steps and that took two nights of 6 hour training sessions. Based on the results, I think I’m getting the best it is capable of and more training wouldn’t help. Besides, I have a suspicion that I over-trained it and now have overfitting.
Something I was very fortunate with but didn’t realize until later was the length of the original reviews. They are fairly consistent in length and structure. By structure I mean paragraph length and having and opening or closing statement. They are mostly in the third person also.
But it was the length that was key. I hit upon the sweet spot of what GPT-2 can produce with the criteria I had. It’s not short form, but they aren’t novels either. 400-600 words is a good experimental length to work with.
Another benefit of training like this was being able to generate results so soon in the process. It was really helpful to know what kind of output I could expect. The first few prompts were a lot of fun and I was pleasantly surprised to see so many glitches and weirdness. I was excited about sharing it, too. I thought that if more people could experiment without having to deal with any of the tech, they might be inspired to explore it as a creative tool.
Into the wild
Now that I had a trained language model, the challenge of deploying it was next. The Colab notebook was fine for my purposes, but getting this in front of average folks was going to be tricky. Again, I had to confront the issue of compute power.
People have high expectations of online experiences now. Patience and attention spans are short. I wasn’t intending a commercial application, but I knew people would expect something close to what they are given in consumer contexts. That meant real-time or near real-time results.
The Hugging Face crew produced a close to real-time GPT-2 demo called Talk to Transformer that was the inspiration for producing an app for this project. That demo produces text results pretty fast, but limited in length.
I made one last lap around the machine learning and artificial intelligence ecosystem, trying to find a cheap way to deploy a GPU support app. Google offers GPUs for their Compute Engine, Amazon has P3 instances of EC2, Microsoft has Azure NC-series, IBM has GPU virtual servers, and there are a bunch of smaller fish in the AI ocean. Looking through so much marketing material from all of those was mind-numbing. Bottom line: it’s very expensive. A whole industry has taken shape.
I also checked my own personal web host, Digital Ocean, but they don’t offer GPU augmentation yet. But, they do offer high end multi-core environments in traditional configurations. Reflecting back on my struggle with the Jetson Nano, I remembered an option when compiling Tensorflow. There was a flag for --config=cuda that could be omitted, yielding a CPU-only version of Tensorflow.
That matters because Tensorflow is at the core of the training and generation functions and is the main reason I needed a GPU. I knew CPU-only would be way too slow for training, but maybe the generator would be acceptable. To test this out, I decided to spin up a high powered Digital Ocean droplet because I would only pay for the minutes it was up and running without a commitment.
I picked an upgraded droplet and configured and secured the Linux instance. I also installed all kinds of dependencies from my original gist because I found that they were inevitably used by some installer. Then I tried installing Tensorflow using the Python package manager pip. That dutifully downloaded Tensorflow 2 and built it from the resulting wheel. Then I tried to install the gpt-2-simple repository that was used in the Colab tutorial. It complained.
The gpt-2-simple code uses Tensorflow 1.x, not 2. It is not forward compatible either. Multiple arcane exceptions were thrown and my usual whack-a-mole skills couldn’t keep up. Downgrading Tensorflow was required, which meant I couldn’t make use of the pre-built binaries from package managers. My need for a CPU-only version was also an issue. Lastly, Tensorflow 1.x doesn’t work with Python 3.8.2. It requires 3.6.5.
I reset the Linux instance and got ready to compile Tensorflow 1.15 from source. Tensorflow uses a build tool called Bazel and v0.26.1 of the tool is specifically required for these needs. I set up Bazel and cloned the repo. After launching the installer, I thought it was going fine but realized it was going to take a looooong time, so I let it run overnight.
The next day I saw that it had failed with OOM (Out Of Memory) in the middle of the night. My Digital Ocean droplet had 8gb of RAM so I bumped that up to 16gb. Thankfully I didn’t have to rebuild the box. I ran it again overnight and this time it worked. It took around 6 hours on a 6 core instance to build Tensorflow 1.15 CPU-only. I was able to downgrade the droplet afterwards so I didn’t have to pay for the higher tier any more. FWIW, compiling Tensorflow cost me about $1.23.
I then loaded gpt-2-simple, the medium GPT-2 (355M) model, and my checkpoint folder from fine tuning in Google Colab. That forms the main engine of the text generator I ended up with. I was able run some manual Python tests and get generated results in ~90 seconds. Pretty good! I had no idea how long it was going to be when I started down this path. My hunch that a CPU-only approach for generation paid off.
Now I had to build a public facing version of it.
The Flask app
Robotron
The success of the project so far came from Python code. So, I decided to deploy it also using Python, as a web application. I’ve been building websites for ~20 years and used many different platforms. When I needed to connect to server processes, I usually did it through an API or some kind of PHP bridge code.
In this case I had my own process I needed to expose and then send data. I figured having a Python web server would make things easier. It was definitely easier at the beginning when was experimenting, but as I progressed the code became more modular and what had been easy was a liability. Flask is a Python library used to build web services (mostly websites) and it has a simple built-in web server. I knew plenty about it, but never used it in a public facing project.
One of the first development decisions I made was to split the web app and text generator into separate files. I could have tried threading but there was too much overhead already with Tensorflow and I doubted my ability to correctly configure a balanced multiple process application in a single instance.* I wanted the web app to serve pages regardless of the state of the text generation. I also wanted them to have their own memory pools that the server would manage, not the Python interpreter.
* I did end up using Threading for specific parts of the generator at a later stage of the project.
Every tutorial I found said I should not use the built-in Flask web server in production. I followed that advice and instead used NGINX and registered the main python script as a WSGI service. After I had already researched the configurations of those, I found this nginx.conf generator that would have made things faster and easier.
After securing the server and getting a basic Hello World page to load, I went through the Let’s Encrypt process to get an SSL certificate. I sketched out a skeleton of the site layout and the pages I would need. The core of the site is a form to enter a text prompt, a Flask route to process the form data, and a route and template to deliver the generated results. Much of the rest is UX and window dressing.
A Flask app can be run from anywhere on the server, not necessarily the /html folder as typically found in a PHP based site. In order to understand page requests and deliver relevant results, a Python script is created that describes the overall environment and the routes that will yield a web page. It is a collection of Python functions, one for each route.
For the actual pages, Flask uses a built-in template engine called Jinja. It is very similar to Twig, which is popular with PHP projects. There are also Python libraries for UI and javascript, but it felt like overkill to grab a bunch of bloatware for this basic site. My CSS and js includes are local and static and limited to what I actually need. There is no inherent template structure in Flask, so I rolled my own with header, footer, utility, and content includes of modular template files.
Based on experience, the effort you put into building out a basic modular approach to templates pays dividends deep into the process. It’s so much easier to manage.
{% include 'header.html' %}
{% include 'navigation.html' %}
<div class="container">
<div class="row">
<div class="col">
<p>This site generates art reviews</p>
</div>
</div>
</div>
{% include 'footer.html' %}
After building out the basic site pages and navigation, I focused on the form page and submission process. The form itself is simple but does have some javascript to validate fields and constrain the length of entries. I didn’t want people to copy and paste a lot of long text. On submission, the form is sent as POST to a separate route. I didn’t want to use URL parameters that a GET request would enable because it’s less secure and generates errors if all the parameter permutations aren’t sanitized.
The form processing is done within the Flask app, in the function for the submission route. It checks and parses the values, stores the values in a SQLite database row, and then sends a task to the RabbitMQ server.
@app.route("/submission", methods=["POST"])
def submission():
payload = request.form
if spam_check:
email = payload["submission_email"]
valid_email = is_email(email, check_dns=True)
if valid_email:
# collecting form results
prompt = payload["prompt"]
# empty checkbox caused error 400 so change parser
if not request.form.get('update_check'):
subscribe = 0
else:
subscribe = 1
eccentricity = int(payload["eccentricity"])
ip = request.environ.get('HTTP_X_REAL_IP', request.remote_addr)
result = {"email": email, "prompt": prompt, "eccentricity": eccentricity, "subscribe": subscribe, "ip": ip}
# create database entry
dConn = sqlite3.connect("XXXXXXXX.db")
dConn.row_factory = sqlite3.Row
cur = dConn.cursor()
# get id of last entry and hash it
cur.execute("SELECT * FROM xxxxxx ORDER BY rowid DESC LIMIT 1")
dRes = cur.fetchone()
id_plus_one = str(int(dRes["uid"]) + 1).encode()
b.update(id_plus_one)
urlhsh = b.hexdigest()
now = str(datetime.now(pytz.timezone('US/Pacific')).strftime("%Y-%m-%d %H:%M:%S"))
# insert into database
try:
cur.execute("INSERT INTO xxxxxx(ip,email,eccentricity,submit_date,prompt,urlhsh,subscribed) VALUES(?,?,?,?,?,?,?)", (ip, email, eccentricity, now, prompt, urlhsh, subscribe))
logging.debug('Prompt %s submitted %s', urlhsh, now)
except sqlite3.Error as error:
logging.exception(error)
dConn.commit()
cur.close()
dConn.close()
# notify task queue
rabbit_connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
rabbit_channel = rabbit_connection.channel()
rabbit_channel.queue_declare(queue='task_queue', durable=True)
rabbit_channel.basic_publish(
exchange='',
routing_key='task_queue',
body=urlhsh,
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
))
rabbit_connection.close()
# confirmation page
return render_template('submission.html', page_title='Request submitted', result=result, copyright_year=today.year)
else:
ed = email + " is not a valid email address"
return render_template('error.html', page_title='Error', error_description=ed, copyright_year=today.year)
else:
return render_template('submission.html', page_title='Request submitted', result="spam", copyright_year=today.year)
Chasing the rabbit
RabbitMQ is a server based message broker that I use to relay data between the submission form and the generator. Although the two scripts are both Python it’s better to have them running separately. There is no magical route between concurrent Python scripts so some sort of data broker is helpful. The first script creates a task and tells RabbitMQ it is ready for processing. The second script checks in with RabbitMQ, finds the task and executes it. It is a middleman between the two scripts.
It does all this very fast, asynchronously, and persistently (in a crash or reboot it remembers the tasks that are queued). Also, it was easy to use. Other options were Redis and Amazon SQS, but I didn’t need the extra overhead or features those offer, or want the dependencies they require.
It was easy to install and I used the default configuration. Specifically I chose to limit connections to localhost for security. That is the default setting, but it can absolutely be set up to allow access from another server. So, I had the option of running my web app on one server and the generator on another. Something to consider when scaling for production or integrating into an existing web property.
sudo apt install rabbitmq
sudo rabbitmq-diagnostics status
Status of node rabbit@xxxxxx ...
Runtime
OS PID: 909
OS: Linux
Uptime (seconds): 433061
Is under maintenance?: false
RabbitMQ version: 3.8.8
Node name: rabbit@xxxxxx
Erlang configuration: Erlang/OTP 23 [erts-11.0.4] [source] [64-bit] [smp:4:4] [ds:4:4:10] [async-threads:64]
Erlang processes: 294 used, 1048576 limit
Scheduler run queue: 1
Cluster heartbeat timeout (net_ticktime): 60
Delivering results
I chose to deliver results with an email notification instead of (near)real-time for a number of reasons. The primary issue was compute time. My best tests were getting results in 93 seconds. That’s with no server load and an ideal environment. If I tried to generate results while people waited on the page, the delay could quickly climb to many minutes or hours. Also, the site itself could hang while chewing on multiple submissions. I don’t have a GPU connected to the server, so everything is going through normal processing cores.
When Facebook first started doing video, the uploading and processing times were much longer than they are now. So, to keep people clicking around on the site they set up notifications for when the video was ready. I took that idea and tried to come up with delayed notifications that didn’t require a login or keeping a tab/window open. That’s very important for mobile users! Nobody is going to sit there holding their phone while this site chews on Tensorflow for 10 minutes.
I also thought of the URL shortener setup where they use random characters to serve as a bookmark for a link. Anybody can use the link and it doesn’t have content or identity signifiers in the URL.
The delivery process was divided into three stages, processing, notification, and presentation.
Processing stage
The main computational engine of the whole project is a python script that checks RabbitMQ for tasks, executes the generating process with Tensorflow, stores the result and sends an email to the user when it is ready.
The reason I have to use threading is because querying RabbitMQ is a blocking process. It’s a very fast and lightweight blocking process, but can absolutely monopolize resources when running. I found that out the hard way because the script kept silently crashing when asking for new tasks at the same time it was using Tensorflow. Trust me, this took a few days of logging and debugging trying to figure out what was causing the generation process to simply disappear without error.
Retrieve prompt from db and start Tensorflow
logging.debug("Rabbit says %r" % body.decode())
# get record using rabbitmq msg
urlhsh = body.decode()
dConn = sqlite3.connect("XXXXXXXX.db")
dConn.row_factory = sqlite3.Row
cur = dConn.cursor()
try:
cur.execute("SELECT * FROM xxxxxx WHERE urlhsh = ?", (urlhsh,))
except sqlite3.Error as error:
logging.exception(error)
dRes = cur.fetchone()
logging.debug("Found %r, processing..." % urlhsh)
row_id = dRes["uid"]
temperature = int(dRes["eccentricity"]) * .1
# the main generation block, graph declaration because threading
with graph.as_default():
result = gpt2.generate(
sess,
run_name='porridge',
length=400,
temperature=temperature,
prefix=dRes["prompt"],
truncate="<|endoftext|>",
top_p=0.9,
nsamples=5,
batch_size=5,
include_prefix=False,
return_as_list=True,
)
result = json.dumps(result)
Because I’m using threading for RabbitMQ, I had to declare a graph for Tensorflow so it had access to the memory reserved for the model.
with graph.as_default():
Store generated result and send notification email
# store generated results in db
now = str(datetime.now(pytz.timezone('US/Pacific')).strftime("%Y-%m-%d %H:%M:%S"))
try:
cur.execute("UPDATE xxxxxx SET gen_date = ?, result = ? WHERE uid = ?", (now, result, row_id))
logging.debug("Published %s on %s", urlhsh, now)
except sqlite3.Error as error:
logging.exception(error)
dConn.commit()
dConn.close()
# send notification email
prompt = dRes["prompt"]
submit_date = dRes["submit_date"]
email_address = dRes["email"]
link = "https://artreviewgenerator.com/review/" + urlhsh
if len(dRes["prompt"]) < 50:
preview_text = prompt
else:
preview_text = prompt[:50] + "..."
email = {
'subject': 'Your results are ready',
'from': {'name': 'Joshua Curry', 'email': 'info@artreviewgenerator.com'},
'to': [
{'email': email_address}
],
"template": {
'id': '383338',
'variables': {
'preview_text': preview_text,
'prompt': prompt,
'submit_date': submit_date,
'link': link
}
},
}
rest_email = [{'email': email_address, 'variables': {}}]
try:
SPApiProxy.smtp_send_mail_with_template(email)
logging.debug("Notification sent to " + email_address)
if int(dRes["subscribed"]) == 1:
SPApiProxy.add_emails_to_addressbook(SP_maillist, rest_email)
except Exception:
logger.error("Problem with SendPulse mail: ", exc_info=True)
I’m using SendPulse for the email service instead of my local SMTP server. There are a couple of good reasons for this. Primarily, I want to use this project to start building an email list of my art and tech projects. So, I chose a service that also has mailing list features in addition to API features. SendPulse operates somewhere between the technical prowess of Twilio and friendly features of MailChimp. Also important is their free tier allows for 12000 transactional emails per month. Most of the other services tend to focus on number of subscribers and the API access is a value add to premium plans. Another thing I liked about them was their verification process for SMTP sending. Avoiding spam and spoofing is seriously considered in their services.
Presentation
Upon receipt of the notification email, users are given a link to see the results that have been generated. If I was designing a commercial service I would have probably chosen to deliver the results in the actual email. It would be more efficient. But, I also wanted people to share the results they get. Having a short url with a permalink easy to copy and paste was important. I also wanted the option of showcasing recent entries. That isn’t turned on now, but I thought it would be interesting to have a gallery in the future. It would also be pretty useful for SEO if I went down that path.
The characters at the end are a hash of the unique id of the SQLite row that was created when the user submission was recorded. Specifically, they are hashed using the Blake2b “message digest” (aka secure hash) with the built-in hashlib library of Python 3. I chose that because the library offers an adjustable character length for that hash type, unlike others that are fixed at long lengths.
from hashlib import blake2b
b = blake2b(digest_size=4)
# get id of last entry and hash it
cur.execute("SELECT * FROM xxxxxx ORDER BY rowid DESC LIMIT 1")
dRes = cur.fetchone()
id_plus_one = str(int(dRes["uid"]) + 1).encode()
b.update(id_plus_one)
urlhsh = b.hexdigest()
When the url is visited, the Flask app loads the page using a simple db retrieval and Jinja template render.
Eventually I would like to offer a gallery of user generated submissions, but I want to gauge participation in the project and get a sense of what people submit. Any time you open up a public website with unmoderated submissions, people can be tempted to submit low value and offensive content.
That is why you see a link beneath the prompt on the results page. I built in a capability for people to report a submission. It’s actually live and immediately blocks the url from loading. So feel free to block your own submissions.
Prologue
This project has been running for a month now without crashing or hitting resource limits. I’m pretty happy with how it turned out, but now have a new mouth to feed by paying for the hosting of this thing.
The actual generator results are interesting to me on a few levels. They reveal intents, biases, and challenges that come from describing our culture at large. They also make interesting mistakes. From my point of view, interesting mistakes are a critical ingredient for creative output.